[kaggle/Flask] 견종 분류 모델 웹에 구현하기
데이터셋 정보
제목 : Dog Breed Image Classification Dataset
데이터셋 링크
https://www.kaggle.com/datasets/wuttipats/dog-breed-image-classification-dataset/data
Dog Breed Image Classification Dataset
A Collection of Dog Images Categorized by Breed
www.kaggle.com
데이터셋 설명
- 이 데이터셋에는 6종류의 개 이미지가 있음
- 파일의 형식은 JPEG이고 이름은 사진 속 개의 품종을 알려줌
- 사진은 견종에 따라 다른 폴더에 저장되어있음

견종 이미지 분류 모델 웹에 구현
시작하기 전
- 원래는 이전 글의 견종 이미지 분류 모델을 이용해 Flask로 웹에 구현해보려고 했음
https://kne-coding.tistory.com/265
[kaggle/TensorFlow] 견종 이미지 분류 모델 구현 - 2
데이터셋 정보 제목 : Dog Breed Image Classification Dataset 데이터셋 링크 https://www.kaggle.com/datasets/wuttipats/dog-breed-image-classification-dataset/data Dog Breed Image Classification Dataset A Collection of Dog Images Categorized by B
kne-coding.tistory.com
- PyCharm을 이용해 가상환경을 설정하고 코드는 작성해보았으나, tensorflow와 keras 버전 문제인지 계속 오류가 떴음
- 며칠동안 여러 방법을 시도해보다 도저히 해결이 안돼서 결국 PyTorch로 모델을 다시 학습, 저장 후 진행함
PyTorch 모델 학습, 저장
필요한 라이브러리 설치¶
- 데이터 처리, 머신 러닝 모델 구축, 성능 평가, 시각화 등 다양한 작업을 수행함
import os
import shutil
import torch
import torchvision
import math
import random
import copy
import time
from PIL import Image
import numpy as np
import torchvision.transforms as transforms
import matplotlib.pyplot as plt # 이미지를 시각화하기 위한 라이브러리
from torchvision import datasets
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import models
from torch.optim import lr_scheduler
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
print('modules loaded')
modules loaded
# PyTorch 버전 확인 및 GPU 확인
torch.__version__
'1.12.1+cu113'
torch.cuda.get_device_name(0) # GPU 이름 체크
'NVIDIA GeForce RTX 2070'
USE_CUDA = torch.cuda.is_available()
print(USE_CUDA)
True
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
BATCH_SIZE = 16
EPOCH = 30
데이터 분할¶
- 데이터 분할을 위한 디렉토리 생성
# 원본 데이터셋 디렉터리 경로
original_dataset_dir = './data'
Dog_Breed_list = os.listdir(original_dataset_dir)
# 원본 데이터셋 디렉터리 내의 클래스 목록 가져오기
classes_list = os.listdir(original_dataset_dir)
# 새로운 디렉터리 생성
base_dir = './splitted'
os.mkdir(base_dir)
# 훈련, 검증, 테스트 데이터 디렉터리 각각 생성
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'val')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 각 클래스(견종) 별로 훈련, 검증, 테스트용 하위 디렉터리 생성
for cls in classes_list:
os.mkdir(os.path.join(train_dir, cls))
os.mkdir(os.path.join(validation_dir, cls))
os.mkdir(os.path.join(test_dir, cls))
print(Dog_Breed_list)
['Bedlington_terrier', 'Bernese_mountain_dog', 'Dandie_Dinmont', 'Gordon_setter', 'Ibizan_hound', 'Norwegian_elkhound']
- 데이터 분할과 클래스별 데이터 수 확인
for cls in classes_list:
# 클래스 디렉터리 경로를 가져옴
path = os.path.join(original_dataset_dir, cls)
# 클래스 디렉터리 내의 파일 목록 가져옴
fnames = os.listdir(path)
# 데이터 분할 비율을 설정함 ( 60% 훈련, 20% 검증, 20% 테스트 )
train_size = math.floor(len(fnames) * 0.6)
validation_size = math.floor(len(fnames) * 0.2)
test_size = math.floor(len(fnames) * 0.2)
# 훈련 데이터 파일 복사
train_fnames = fnames[:train_size]
print("Train size(",cls,"): ", len(train_fnames))
for fname in train_fnames:
src = os.path.join(path, fname) # 원본 이미지 파일 경로
dst = os.path.join(os.path.join(train_dir, cls), fname) # 목적지(훈련 데이터) 파일 경로
shutil.copyfile(src, dst) # 이미지 파일 복사
# 검증 데이터 파일 복사
validation_fnames = fnames[train_size:(validation_size + train_size)]
print("Validation size(",cls,"): ", len(validation_fnames))
for fname in validation_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(validation_dir, cls), fname)
shutil.copyfile(src, dst)
# 테스트 데이터 파일 복사
test_fnames = fnames[(train_size+validation_size):(validation_size + train_size +test_size)]
print("Test size(",cls,"): ", len(test_fnames))
for fname in test_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(test_dir, cls), fname)
shutil.copyfile(src, dst)
Train size( Bedlington_terrier ): 81 Validation size( Bedlington_terrier ): 27 Test size( Bedlington_terrier ): 27 Train size( Bernese_mountain_dog ): 78 Validation size( Bernese_mountain_dog ): 26 Test size( Bernese_mountain_dog ): 26 Train size( Dandie_Dinmont ): 69 Validation size( Dandie_Dinmont ): 23 Test size( Dandie_Dinmont ): 23 Train size( Gordon_setter ): 69 Validation size( Gordon_setter ): 23 Test size( Gordon_setter ): 23 Train size( Ibizan_hound ): 74 Validation size( Ibizan_hound ): 24 Test size( Ibizan_hound ): 24 Train size( Norwegian_elkhound ): 78 Validation size( Norwegian_elkhound ): 26 Test size( Norwegian_elkhound ): 26
데이터 증강¶
# 원본 데이터셋 디렉토리 경로
original_dataset_dir = './splitted'
# 클래스(카테고리) 목록 가져오기
classes_list = os.listdir(original_dataset_dir)
print(classes_list)
['test', 'train', 'val']
# 데이터 증강을 위한 변환 정의
data_transforms = transforms.Compose([
transforms.RandomRotation(degrees=40),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomResizedCrop(size=(224, 224), scale=(0.8, 1.0)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
transforms.RandomAffine(degrees=0, translate=(0.2, 0.2)),
transforms.RandomPerspective(distortion_scale=0.2),
transforms.ToTensor() ])
# 각 클래스(카테고리) 별로 데이터 증강하여 저장
for cls in classes_list:
if cls == 'test' :
continue
# 클래스 디렉토리 경로 가져오기
class_dir = os.path.join(original_dataset_dir, cls)
for dog in Dog_Breed_list :
file_dir = os.path.join(class_dir, dog)
# 클래스 디렉토리 내의 파일 목록 가져오기
fnames = os.listdir(file_dir)
for fname in fnames:
src = os.path.join(file_dir, fname) # 원본 이미지 파일 경로
try :
# 이미지를 열어서 읽을 수 있는지 확인함
img = Image.open(src)
# 데이터 증강 적용
augmented_img = data_transforms(img)
# 저장할 경로 설정
dst = os.path.join(file_dir,("aug_"+fname)) # 목적지(증강 데이터) 파일 경로
# 이미지 저장
torchvision.utils.save_image(augmented_img, dst)
except Exception as e:
print(f"Error opening {src}: {e}")
pass
print("데이터 증강이 완료되었습니다.")
데이터 증강이 완료되었습니다.
Transfer Learning 모델 학습¶
- Transfer Learning을 위한 준비
data_transforms = {
'train': transforms.Compose([transforms.Resize([224,224]),
transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(),
transforms.RandomCrop(180), transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]),
'val': transforms.Compose([transforms.Resize([224,224]),
transforms.RandomCrop(180), transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ])
}
data_dir = './splitted'
image_datasets = {x: ImageFolder(root=os.path.join(data_dir, x), transform=data_transforms[x]) for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=BATCH_SIZE, shuffle=True, num_workers=4) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
class_names
['Bedlington_terrier', 'Bernese_mountain_dog', 'Dandie_Dinmont', 'Gordon_setter', 'Ibizan_hound', 'Norwegian_elkhound']
- Pre-Trained Model 불러오기
resnet = models.resnet50(pretrained=True)
num_ftrs = resnet.fc.in_features
resnet.fc = nn.Linear(num_ftrs, 33)
resnet = resnet.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.Adam(filter(lambda p: p.requires_grad, resnet.parameters()), lr=0.0001)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
C:\Users\ICLab\anaconda3\envs\GPU_cuda\lib\site-packages\torchvision\models\_utils.py:209: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and will be removed in 0.15, please use 'weights' instead.
f"The parameter '{pretrained_param}' is deprecated since 0.13 and will be removed in 0.15, "
C:\Users\ICLab\anaconda3\envs\GPU_cuda\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
- Pre-Trained Model의 일부 Layer Freeze하기
ct = 0
for child in resnet.children():
ct += 1
if ct < 6:
for param in child.parameters():
param.requires_grad = False
- Transfer Learning 모델 학습과 검증을 위한 함수
def train_resnet(model, criterion, optimizer, scheduler, num_epochs=25):
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('-------------- epoch {} ----------------'.format(epoch+1))
since = time.time()
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(DEVICE)
labels = labels.to(DEVICE)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss/dataset_sizes[phase]
epoch_acc = running_corrects.double()/dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('Completed in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model
- 모델 학습을 실행 및 그래프 그리기
model_resnet50 = train_resnet(resnet, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=EPOCH)
torch.save(model_resnet50, 'resnet50.pt')
-------------- epoch 1 ---------------- train Loss: 0.8595 Acc: 0.8229 val Loss: 0.1772 Acc: 0.9497 Completed in 0m 21s -------------- epoch 2 ---------------- train Loss: 0.2426 Acc: 0.9165 val Loss: 0.2088 Acc: 0.9430 Completed in 0m 18s -------------- epoch 3 ---------------- train Loss: 0.1927 Acc: 0.9443 val Loss: 0.2546 Acc: 0.9128 Completed in 0m 18s -------------- epoch 4 ---------------- train Loss: 0.1368 Acc: 0.9566 val Loss: 0.1182 Acc: 0.9564 Completed in 0m 21s -------------- epoch 5 ---------------- train Loss: 0.0874 Acc: 0.9733 val Loss: 0.1218 Acc: 0.9698 Completed in 0m 20s -------------- epoch 6 ---------------- train Loss: 0.1028 Acc: 0.9699 val Loss: 0.2158 Acc: 0.9396 Completed in 0m 19s -------------- epoch 7 ---------------- train Loss: 0.0772 Acc: 0.9755 val Loss: 0.2099 Acc: 0.9430 Completed in 0m 20s -------------- epoch 8 ---------------- train Loss: 0.0761 Acc: 0.9755 val Loss: 0.1309 Acc: 0.9597 Completed in 0m 21s -------------- epoch 9 ---------------- train Loss: 0.0732 Acc: 0.9800 val Loss: 0.1420 Acc: 0.9530 Completed in 0m 20s -------------- epoch 10 ---------------- train Loss: 0.0417 Acc: 0.9900 val Loss: 0.1062 Acc: 0.9564 Completed in 0m 20s -------------- epoch 11 ---------------- train Loss: 0.0427 Acc: 0.9889 val Loss: 0.1096 Acc: 0.9631 Completed in 0m 20s -------------- epoch 12 ---------------- train Loss: 0.0280 Acc: 0.9933 val Loss: 0.1029 Acc: 0.9664 Completed in 0m 20s -------------- epoch 13 ---------------- train Loss: 0.0235 Acc: 0.9967 val Loss: 0.0918 Acc: 0.9664 Completed in 0m 22s -------------- epoch 14 ---------------- train Loss: 0.0294 Acc: 0.9944 val Loss: 0.0776 Acc: 0.9799 Completed in 0m 19s -------------- epoch 15 ---------------- train Loss: 0.0308 Acc: 0.9944 val Loss: 0.1047 Acc: 0.9597 Completed in 0m 20s -------------- epoch 16 ---------------- train Loss: 0.0309 Acc: 0.9978 val Loss: 0.0961 Acc: 0.9698 Completed in 0m 19s -------------- epoch 17 ---------------- train Loss: 0.0242 Acc: 0.9967 val Loss: 0.1163 Acc: 0.9631 Completed in 0m 19s -------------- epoch 18 ---------------- train Loss: 0.0269 Acc: 0.9933 val Loss: 0.1049 Acc: 0.9597 Completed in 0m 18s -------------- epoch 19 ---------------- train Loss: 0.0172 Acc: 0.9967 val Loss: 0.0774 Acc: 0.9698 Completed in 0m 20s -------------- epoch 20 ---------------- train Loss: 0.0208 Acc: 0.9978 val Loss: 0.1180 Acc: 0.9631 Completed in 0m 18s -------------- epoch 21 ---------------- train Loss: 0.0213 Acc: 0.9967 val Loss: 0.0970 Acc: 0.9732 Completed in 0m 19s -------------- epoch 22 ---------------- train Loss: 0.0294 Acc: 0.9933 val Loss: 0.1189 Acc: 0.9564 Completed in 0m 18s -------------- epoch 23 ---------------- train Loss: 0.0214 Acc: 0.9933 val Loss: 0.1043 Acc: 0.9664 Completed in 0m 18s -------------- epoch 24 ---------------- train Loss: 0.0257 Acc: 0.9933 val Loss: 0.1110 Acc: 0.9597 Completed in 0m 19s -------------- epoch 25 ---------------- train Loss: 0.0312 Acc: 0.9922 val Loss: 0.0858 Acc: 0.9698 Completed in 0m 20s -------------- epoch 26 ---------------- train Loss: 0.0193 Acc: 0.9967 val Loss: 0.0784 Acc: 0.9765 Completed in 0m 20s -------------- epoch 27 ---------------- train Loss: 0.0142 Acc: 1.0000 val Loss: 0.1110 Acc: 0.9664 Completed in 0m 18s -------------- epoch 28 ---------------- train Loss: 0.0255 Acc: 0.9955 val Loss: 0.0980 Acc: 0.9732 Completed in 0m 18s -------------- epoch 29 ---------------- train Loss: 0.0203 Acc: 0.9944 val Loss: 0.1002 Acc: 0.9631 Completed in 0m 19s -------------- epoch 30 ---------------- train Loss: 0.0215 Acc: 0.9944 val Loss: 0.0965 Acc: 0.9832 Completed in 0m 18s Best val Acc: 0.983221
모델 평가¶
def evaluate(model, test_loader):
model.eval() # 모델을 평가 모드로 설정 (드롭아웃 및 배치 정규화를 비활성화)
test_loss = 0 # 테스트 손실 초기화
correct = 0 # 정확한 예측 횟수 초기화
with torch.no_grad(): # 그라디언트 계산 비활성화 (테스트 모드에서는 필요 없음)
for data, target in test_loader: # 테스트 데이터 배치를 순회
data, target = data.to(DEVICE), target.to(DEVICE) # 데이터와 타겟을 GPU로 이동 (DEVICE는 미리 정의되어 있어야 함)
output = model(data) # 모델로부터 예측값 얻음
# 교차 엔트로피 손실 계산 및 누적
test_loss += F.cross_entropy(output,target, reduction='sum').item()
# 예측값에서 가장 높은 확률을 가진 클래스 선택
pred = output.max(1, keepdim=True)[1]
# 정확한 예측 횟수 누적
correct += pred.eq(target.view_as(pred)).sum().item()
# 전체 테스트 데이터에 대한 평균 손실 및 정확도 계산
test_loss /= len(test_loader.dataset)
test_accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuracy # 평균 손실과 정확도 반환
# 이미지 변환 파이프라인 정의
transform_resNet = transforms.Compose([
transforms.RandomResizedCrop(size=(224, 224), scale=(0.8, 1.0)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 테스트 데이터셋을 로드하고 변환 파이프라인을 적용
test_resNet = ImageFolder(root='./splitted/test', transform=transform_resNet)
# 테스트 데이터 로더 설정
test_loader_resNet = torch.utils.data.DataLoader(test_resNet, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
resnet50=torch.load('resnet50.pt')
resnet50.eval()
test_loss, test_accuracy = evaluate(resnet50, test_loader_resNet)
print('ResNet test acc: ', test_accuracy)
ResNet test acc: 98.65771812080537
이미지 불러온 후 예측하기¶
from PIL import Image
def preprocess_image(image_path):
# 이미지 불러오기
image = Image.open(image_path)
# 이미지를 모델의 입력 크기에 맞게 조정
preprocess = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = preprocess(image)
# 배치 차원 추가 (이미지를 하나의 배치로 처리)
image = image.unsqueeze(0)
return image
def predict_image(image_path, model):
image = preprocess_image(image_path)
# 모델 및 입력 데이터를 모델의 디바이스로 이동
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
image = image.to(device)
# 모델 예측
with torch.no_grad():
output = model(image)
# 확률 분포에서 가장 높은 확률을 가지는 클래스를 찾습니다.
_, predicted_class = output.max(1)
return predicted_class.item()
for i in range(1,9) :
image_path = './image/image'+str(i)+'.jpg'
print(image_path)
./image/image1.jpg ./image/image2.jpg ./image/image3.jpg ./image/image4.jpg ./image/image5.jpg ./image/image6.jpg ./image/image7.jpg ./image/image8.jpg
# 미리 학습된 ResNet 모델 로드
resnet50=torch.load('resnet50.pt')
resnet50.eval()
# 이미지 예측
for i in range(1,9) :
image_path = './image/image'+str(i)+'.jpg'
predicted_class = predict_image(image_path,resnet50)
print(f'예측된 클래스: {class_names[predicted_class]}')
예측된 클래스: Ibizan_hound 예측된 클래스: Bedlington_terrier 예측된 클래스: Norwegian_elkhound 예측된 클래스: Norwegian_elkhound 예측된 클래스: Dandie_Dinmont 예측된 클래스: Ibizan_hound 예측된 클래스: Gordon_setter 예측된 클래스: Bernese_mountain_dog
예측 수행한 이미지

Flask 이용해서 웹에 서빙
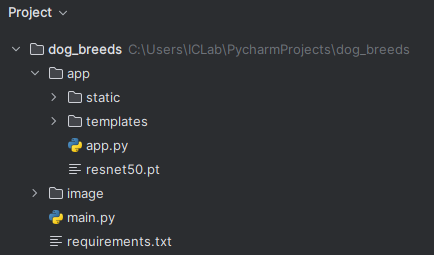
- 아래의 사진은 해당 프로젝트의 디렉터리 구조
main.py
- 학습된 ResNet 모델을 로드하여 이미지를 입력받아 예측을 수행함
- 예측 수행 후 테스트로 출력하여 결과를 알려줌 (결과 출력 테스트용)
from torchvision import models
import time
import copy
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
import torchvision.transforms as transforms
import os
from PIL import Image
# 미리 학습된 ResNet 모델 로드
resnet50 = torch.load('./resnet50.pt')
resnet50.eval()
class_names = {0:'Bedlington_terrier',
1:'Bernese_mountain_dog',
2:'Dandie_Dinmont',
3:'Gordon_setter',
4:'Ibizan_hound',
5:'Norwegian_elkhound'}
def predict_image(image_path):
# 이미지를 모델의 입력 크기에 맞게 조정
preprocess_image = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = Image.open(image_path) # 이미지 불러오기
image = preprocess_image(image)
image = image.unsqueeze(0) # 배치 차원 추가 (이미지를 하나의 배치로 처리)
# 모델 및 입력 데이터를 모델의 디바이스로 이동
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
resnet50.to(device)
image = image.to(device)
# 모델 예측
with torch.no_grad():
output = resnet50(image)
# 확률 분포에서 가장 높은 확률을 가지는 클래스를 찾습니다.
_, predicted_class = output.max(1)
return class_names.get(predicted_class.item(), 'Unknown')
# # 이미지 예측
# for i in range(1, 9):
# image_path = './image/image' + str(i) + '.jpg'
# predicted_class = predict_image(image_path)
#
# print(f'예측된 클래스: {predicted_class}')
index.html
- 이미지 업로드를 위한 웹 페이지
- '파일 선택'을 통해 이미지 업로드 후 파일명을 확인하고 '견종 분류 예측하기!'버튼을 클릭함
- 클릭시 result.html 페이지로 이동함
<!DOCTYPE html>
<html>
<head>
<title>견종 분류하기</title>
</head>
<body>
<div class="container">
<h1>견종 분류하기</h1>
<h2>이미지 업로드</h2>
{% if filename %}
<div>
<img src="{{filename}}">
</div>
<div>
<p>{{label}} {{probability}}</p>
</div>
{% endif %}
<form method="post" action="/result" enctype="multipart/form-data">
<input type="file" name="file">
<input type="submit" value="견종 분류 예측하기!">
</form>
</div>
</body>
</html>
result.html
- 사용자가 업로드한 이미지와 함께 모델 예측 결과가 표시됨
- 아래의 '다른 사진 예측하기' 버튼을 통해 이미지 업로드 페이지로 이동할 수 있음
<!DOCTYPE html>
<html>
<head>
<title>이미지 예측 결과</title>
</head>
<body>
<h1>이미지 예측 결과</h1>
<!-- 업로드된 이미지 표시 -->
<h2>개 이미지:</h2>
<img src="{{ uploaded_image }}" alt="Uploaded Image" style="max-width: 400px;">
<!-- 모델 예측 결과 표시 -->
<h2>예측한 견종:</h2>
<p>{{ predicted_class }}</p>
<!-- 이미지 업로드 페이지로 이동하는 링크 -->
<p><a href="/">다른 사진 예측하기</a></p>
</body>
</html>
app.py
- 기본 페이지를 index.html로 설정함
- 해당 파일의 <form>태그를 보면 action=result 이므로 파일을 업로드 하면 @app.route('/result',~) 부분이 실행됨
- 업로드 된 이미지는 파일 경로를 생성하여 static - IMG 폴더에 저장됨
- predicted_class에 이미지 견종 예측 결과를 저장함
- result.html로 해당 결과와 파일 이미지 경로를 포함하여 렌더링함
from flask import Flask, render_template, request, jsonify
from main import predict_image
import torch
import torchvision.models as models
import joblib
import os
import cv2
import numpy as np
app = Flask(__name__)
IMG_FOLDER = os.path.join('static', 'IMG')
app.config['UPLOAD_FOLDER'] = IMG_FOLDER
@app.route('/')
def index():
return render_template('index.html')
@app.route('/result', methods=['POST'])
def upload():
uploaded_file = request.files['file']
if uploaded_file.filename != '':
file_path = f"./static/IMG/{uploaded_file.filename}"
print(file_path)
uploaded_file.save(file_path)
predicted_class = predict_image(file_path)
up_img = os.path.join(app.config['UPLOAD_FOLDER'], uploaded_file.filename)
# result.html을 렌더링하고 업로드된 이미지와 예측 결과 전달
return render_template('result.html', uploaded_image=up_img, predicted_class=predicted_class)
else:
return jsonify({'error': 'No file selected'})
if __name__ == '__main__':
app.run(debug=True)
결과 확인하기
- 접속시 화면

- 파일 선택했을때의 상태

- 이미지 예측 결과

- 업로드 이미지 폴더에 저장