
- c++
- Database_Design
- Univ._Study
- 오블완
- Python
- Linux
- datastructure
- 2023_1st_Semester
- Operating_System
- app
- Kubernetes
- Artificial_Intelligence
- Personal_Study
- 티스토리챌린지
- programmers
- C
- codingTest
- Baekjoon
- tensorflow
- Java
- Image_classification
- cloud_computing
- 자격증
- Android
- Algorithm
- kubeflow
- SingleProject
- study
- 리눅스마스터2급
- Unix_System
코딩 기록 저장소
[쿠버네티스] PART3. 한 걸음 더 나아가기 본문
목차
1. 쿠버네티스의 CI/CD
01. CI/CD란?
- CI/CD가 등장하기 전, 개발할 때는 개발자들이 소스 코드가 저장된 저장소에 접근해서 커밋을 통해 사용 권한을 얻고, 이후 수정한 내용을 빌드하고 테스트하는 과정을 거침
- 개발 중에는 별도의 품질 관리를 수행하지 않기 때문에 테스트 과정 중에 오류가 발생하는 경우가 많았음
- 그래서 CI/CD가 등장하게 됨
CI/CD 개념
CI
- Continuous Integration의 약자로 지속적 통합을 의미함
- 오류 수정 혹은 새로운 기능을 테스트하고 깃허브 같은 저장소에 배포하는 과정을 의미함
- Travis CI, Bamboo, 젠킨스(Jenkins) 등 같은 도구를 사용하는데, 그중 젠킨스를 가장 많이 사용함
- CI의 핵심
- 빠른 개발과 배포
- 애플리케이션을 운영하다 보면 새로운 기능을 추가하거나 기존의 기능을 수정하고 배포해야 하는 상황이 많이 발생함
- 빈번한 수정과 테스트를 빠르면서도 효율적으로 진행하도록 도와줌 - 자동화
- 소스 코드를 수정한 후 빌드하고 테스트하는 과정을 자동화 시켜줌
- 빠른 개발과 배포
- CI의 목적
- 소스 코드 파일, 라이브러리, 구성 파일 및 스크립트를 포함해 전체 코드를 포함하는 프로그램 또는 버전 관리
- 프로그램 빌드의 자동화
- 자동화된 테스트
CD
- Continuous Delivery 또는 Continuous Deployment의 약자로 지속적 배포를 의미함
- 테스트까지 완료된 소스 코드를 개발 환경과 운영 환경에 배포하는 것을 의미함
- 개발 환경과 운영 환경을 분리하는 이유는 안정성 때문
- 개발 환경에 배포해 오류가 발생하는지 확인하고 문제가 없다면 운영 환경에 배포하게 됨
- Continuous Delivery는 사람의 손이 필요한 수동 배포, Continuous Deployment 모든 과정이 자동화로 처리됨
- 빠르고 정확하게 배포를 도와주는 자동화 도구를 사용하는데, 대표적으로 ArgoCD를 많이 사용함
- 깃허브, 깃옵스 및 깃옵스 리포지터리 역할
- 깃허브(GitHub) : 소프트웨어를 개발할때 소스 코드 버전을 관리하기 위한 원격 저장소
- 깃옵스(GitOps) : 깃허브에 있는 소스 코드를 쿠버네티스 클러스터에 그대로 반영함
- 깃옵스 리포지터리(GitOps Repository) : 매니페스트 파일들이 모여 있는 저장소. 깃옵스는 매니페스틀를 이용해 쿠버네티스 클러스터에 자동으로 배포(반영)하므로 이를 저장하기 위한 저장소
02. 지속적 통합 자동화 도구, 젠킨스
젠킨스
- 소프트웨어 개발 시 지속적으로 통합 서비스를 제공하는 CI 툴
- 다수의 개발자가 개발한 소스 코드를 커밋/빌드하고 개발 환경에 배포하는 일 등을 자동화함
- 장점
- 프로젝트 환경에서 컴파일 오류 검출
- 테스트를 자동으로 수행
- 코딩 규약 준수 여부 체크(문법 체크)
- 소스 변경에 따른 성능 변화 감시
- 개발자의 소스 통합 및 배포
젠킨스 설치하기
- 리눅스 패키지를 최신 상태로 업데이트함
- 최신 상태로 업데이트하면 설치할 패키지(소프트웨어)를 최신 버전으로 가져올 수 있음
sudo apt update - JDK를 설치함
- openjdk 17버전으로 설치함
sudo apt install -y openjdk-17-jre-headless
- 설치가 잘 된것을 확인할 수 있음
java -version
- 젠킨스를 설치하기 위해 필요한 패키지에 접근하기 위해 GPG 키를 추가함
- 리눅스에서 설치하려는 패키지가 기본 리포지터리에 포함되지 않을 수 있음
- 이때 add-apt-repository 명령어를 사용하면 설치하려는 소프트웨어에 대한 접근 권한을 부여함
- 이와 유사한 역할을 하는 것이 GPG(GNU Privacy Guard, GnuPG)
- GPG는 디지털 암호화 및 서명 서비스를 제공하는 OpenPGP
wget -q -O - https://pkg.jenkins.io/debian/jenkins.io-2023.key |sudo gpg --dearmor -o /usr/share/keyrings/jenkins.gpg
- 명령어의 옵션
- wget : Web Get의 약어로 웹에서 파일을 내려받을 때 사용하는 명령어
- -q : quit의 약어로 명령어 실행이 완료되면 별다른 출력 없이 종료함
- -o : wget을 통해 내려받을 때 저장되는 파일명은 URL의 마지막 / 뒤에 오는 단어로 함. 따라서 jenkins.io.key라는 이름으로 저장됨
- | : 앞의 명령어의 실행 결과를 뒤의 명령어의 입력으로 넘김
- gpg - dearmor : gpg 키를 apt가 인식할 수 있는 형식으로 변환함
- /usr/share/keyrings/jenkins.gpg : jenkins.gpg 키를 추가함
- 명령어의 옵션
- 젠킨스 패키지 저장소 주소를 sources.list에 추가해야 함
sudo sh -c 'echo deb [signed-by=/usr/share/keyrings/jenkins.gpg] http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
- 명령어의 옵션
- sudo sh : 셸 스크립트로 작성된 파일을 실행하는 명령어
- -c : 파일이 존재하면 덮어쓰기를 하지 않는 옵션
- echo : 문자열을 컴퓨터 터미널에 출력하는 명령어
- deb : deb은 모든 Debian 기반 배포에서 사용하는 설치 패키지 형식. 우분투 리포지터리에는 우분투 소프트웨어 센터, apt 및 app-get 유틸리티를 사용해 설치할 수 있는 수천 개의 deb 패키지가 포함되어 있음
- [signed-by=/usr/share/keyrings/jenkins.gpg] : GPG 키를 사용해 apt가 내려받은 저장소의 파일을 확인(접근할 수 있는지, 안전한지 등)함
- http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list : /etc/apt/sources.list.d 파일에 젠킨스 저장소 주소(http://pkg.jenkins.io/debian-stable binary/)를 추가함
- 명령어의 옵션
- 젠킨스를 설치함
sudo apt install jenkins
- 젠킨스의 상태를 확인함
- Active로 Running 상태를 보여줌
- Inactive 상태라면 sudo systemctl start jenkins.service 명령어로 젠킨스를 시작할 수 있음
sudo systemctl status jenkins
젠킨스 설정하기
- 젠킨스 설치를 완료했고 이제 젠킨스를 구성해야 함
- 브라우저에서 마스터 노드의 IP에 접근함 (2가지 방법중 하나로 하면 됨)
- Hyper-V 관리자에서 master에 접속해 파이어폭스(Firefox) 브라우저에서 localhost:8080에 접근
- Hyper-V가 설치된 컴퓨터의 브라우저에서 마스터노드의 IP:8080으로 접근 - 아래 화면같이 administrator password 묻는 화면이 나오면 패스워드를 입력한 후 Continue를 클릭함
- 패스워드는 다음 명령어로 확인할 수 있음
sudo cat /var/lib/jenkins/secrets/initialAdminPassword
- 기본 플러그인 설치를 진행함
- Administrator password를 입력하면 플러그인 설치와 관련된 옵션들이 나타남
- Install suggested plugins를 클릭해 설치 진행
- 설치 진행

- 사용자와 패스워드를 설정

- 접속할 수 있는 URL을 보여줌
- Save and Finish를 클릭함
- 젠킨스 사용 준비가 완료되었다는 화면을 보여줌
- Start using Jenkins를 클릭
- 젠킨스 접속 화면
젠킨스 사용하기
깃허브와 연동하기
- 젠킨스는 빌드를 자동화하는 툴이므로 소스 코드가 저장된 저장소와 연계해야 함
- 깃허브를 저장소로 사용함
- 깃허브에 연동하기 위해 먼저 깃허브에 접속해 로그인함
- 젠킨스에서 깃허브에 접속할 수 있는 토큰을 생성해야 함
- 오른쪽 상단의 프로필 → Settings
- 왼쪽 메뉴 하단의 Developer settings를 선택

- Personal access tokens에서 Tokens을 클릭 후 Generate new token(classic) 클릭함

- Note에 토큰 이름을 지정하고 Expiration 부분은 No expiration을 선택함
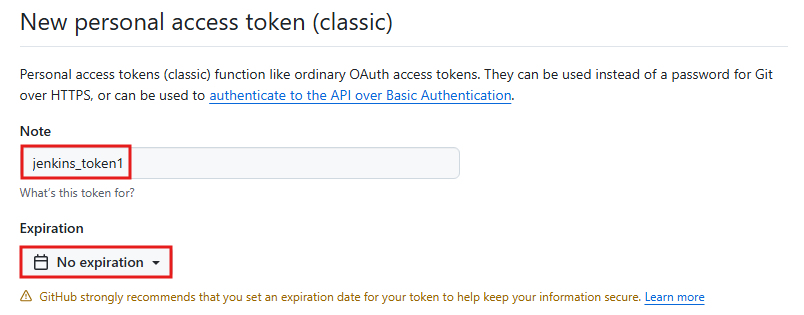
- scopes에서는 다음과 같은 항목을 선택한 후 Generate token을 클릭함
- scopes는 젠킨스에서 깃허브에 접속해 사용할 수 있는 권한에 관한 것, 리포지터리와 자동 빌드를 위한 권한만 체크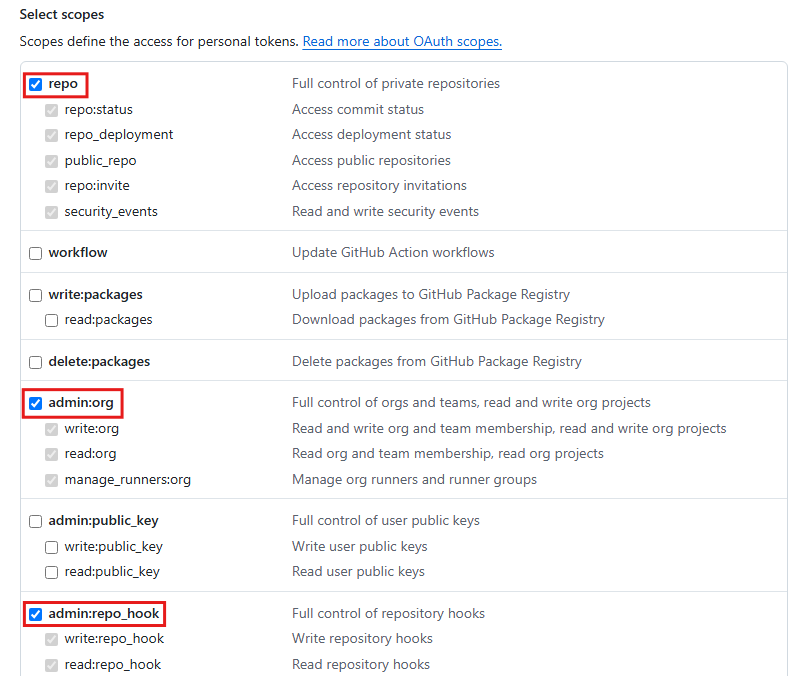
- 생성된 토큰을 저장해둠

- 젠킨스로 이동해 깃허브와 연결함
- 젠킨스 화면의 왼쪽 메뉴에서 Manage Jenkins를 클릭함
- System Configuration 에서 System을 클릭

- 화면을 하단으로 이동하면 GitHub라는 메뉴가 있음 Add GitHub Server > GitHub Server를 선택함

- 깃허브 접속을 위한 Credential 설정
- Name : access_github
- API URL : https://api.github.com
- Credentials : Add > Jenkins를 선택
- 깃허브에 연결하기 위한 권한을 설정할 수 있는 화면이 나타남. 다음과 같이 설정함
- Domain은 그대로 두고, Kind는 Secret text를 선택함
- Secret에서는 앞에서 저장했던 토큰을 입력하고, ID는 토큰 이름을 지정함
- 이후 Add를 클릭함
- 이후 Credentials 아래 리스트 박스를 클릭하면 생성했던 jenkins_token1이 보임. 이것을 선택함

- Test connection 버튼을 클릭해 정상적으로 연결되는 것을 확인한 후 Save 버튼을 클릭함
- 테스트 결과 'Credentials verified for user [user ID], rate limit: 4999'가 나타나면 연결에 성공한 것
프로젝트 생성하기
- 이제 젠킨스에서 소스 코드를 자동 빌드하는 프로젝트 생성함
- 젠킨스 메인 화면의 왼쪽 메뉴에서 New Item을 클릭함

- 다음 메뉴에서 item name을 입력한 후 Freestyle project를 선택하고 OK 버튼을 클릭

- 빌드 방법을 지정하기 위해 Triggers를 선택함
- 'Github hook trigger for GITScm polling'을 체크하면 왼쪽 하단에 save와 apply가 나타나는데, save를 클릭
- 그러면 다음과 같은 메뉴가 나타나는데 Configure를 클릭함
- 깃허브에 접속할 수 있는 권한을 생성함
- '소스 코드 관리'로 이동해 Credentials에서 Add > Jenkins를 클릭함
- 그러면 다음과 같은 창이 뜨는데 Kind에 Username with password를 선택함

- 다음과 같은 항목만 채운 상태에서 Add를 클릭함
- 이때 Username에는 깃허브 계정을 입력하고 Password에는 토큰을 입력함 - 이제 다음과 같이 -none-이 위치한 리스트 박스를 클릭하면 생성했던 credential이 나타나는데 본인의 깃허브 계정을 선택

- 권한 설정이 완료되었으므로 이제 깃허브 주소가 필요함
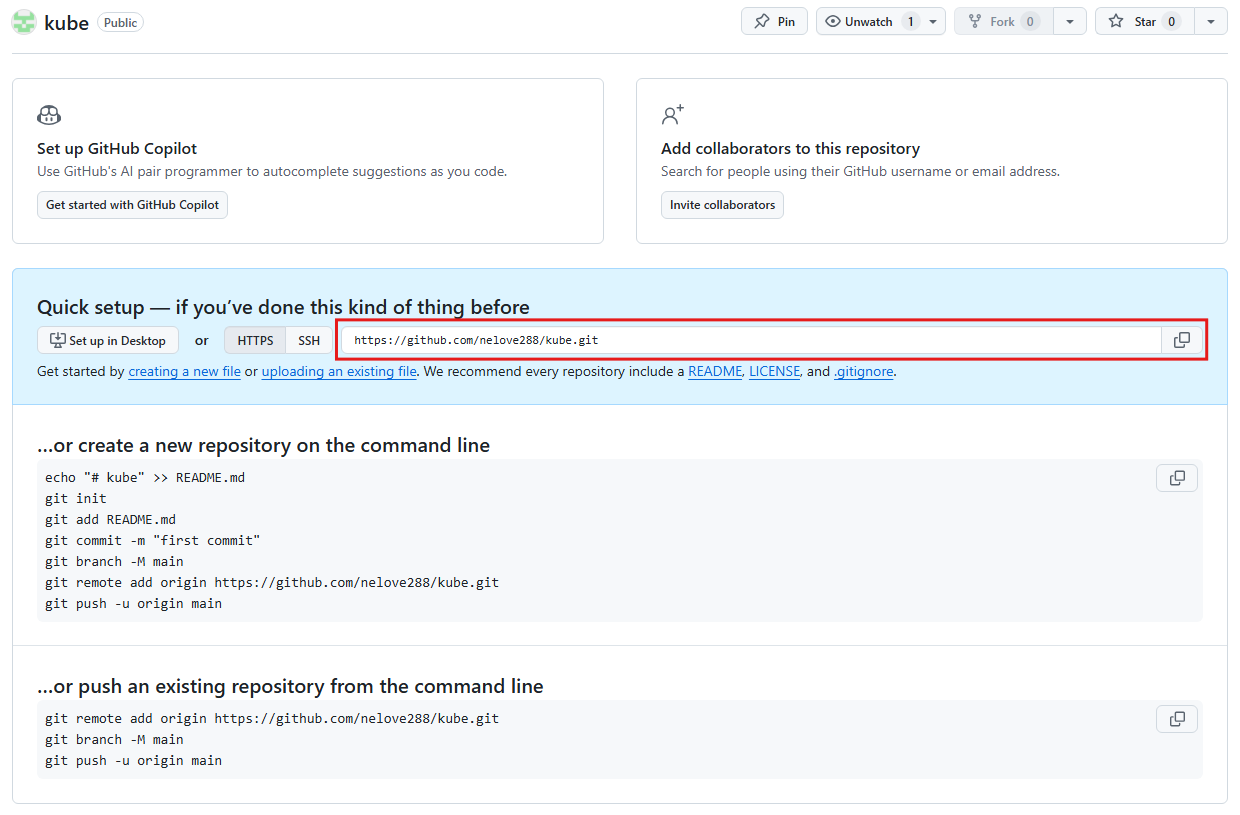
- URL을 확인하기 위해 깃허브에 다시 접속해 깃허브 아이콘을 클릭한 후 New를 클릭함
- Repository name을 입력한 후 하단의 Create repository를 클릭함

- 이후 다음과 같은 주소를 보여줌. 이 주소를 복사함
- 다시 젠킨스로 이동해 Source Code Management로 이동하고 Repository URL 항목에 앞에서 복사해 둔 주소를 입력함
- 입력후 Advanced...를 클릭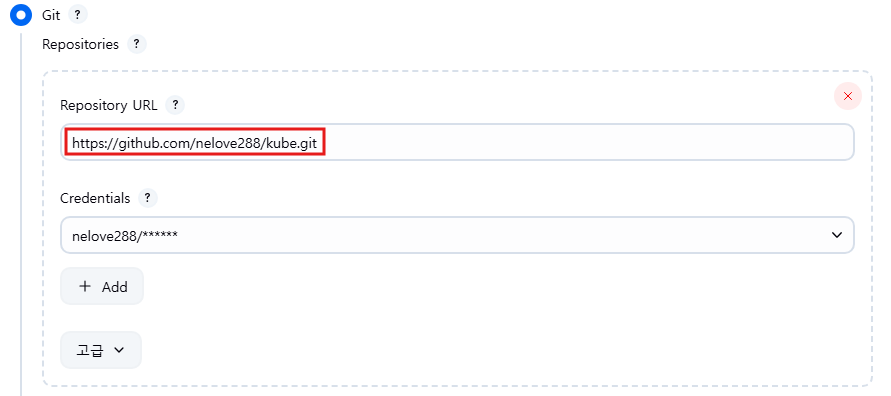
- Branches to build에는 */main을 입력한 후 Save를 클릭함
- 기본은 master이지만 깃허브의 branch 이름을 입력함
빌드 도구 설정하기
- 젠킨스는 지속적 통합, 프로젝트 빌드, 테스트 실행, 배포 등의 작업을 자동화함
- 이것이 가능하도록 메이븐(Maven), 앤트(Ant), 그래들(Gradle) 같은 빌드 도구를 이용하고, 깃허브, SVN(SubVersion) 같은 형상 관리 툴을 지원함
- 젠킨스에서 실행될 빌드 도구를 설정해야함
| 앤트 빌드 도구의 특징 | 메이븐 빌드 도구의 특징 | 그래들 빌드 도구의 특징 |
| - XML 기반으로 빌드 스크립트를 작성함 - 간단하고 사용이 쉬움 - 프로젝트 규모가 클 경우 스크립트 관리나 빌드 과정이 복잡함 |
- XML 기반으로 작성함 - 생명 주기(Lifecycle)와 프로젝트 객체 모델(POM, Project Object Model)이란 개념이 도입됨 - 상대적으로 학습 장벽이 높음 - 라이브러리가 서로 의존적이면 사용이 복잡함 |
- 라이브러리 의존성 관리를 위한 다양한 방법을 제공함 - 빌드 스크립트를 XML이 아닌 JVM에서 동작하는 스크립트 언어 '그루비' 기반의 DSL을 사용함 - 사용이 쉽고 빌드 과정이 간단함 |
- wget 명령어를 이용해 /tmp 디렉터리에 그래들 설치 파일(zip 파일)을 내려받음
- 이때 -P는 파일을 저장할 디렉터리를 지정할 때 사용하는 옵션
wget https://services.gradle.org/distributions/gradle-7.4.2-bin.zip -P /tmp - 모두 내려받았으면 /opt/gradle 디렉터리에 압축을 해제함
sudo unzip -d /opt/gradle /tmp/gradle-*.zip - /opt/gradle/gradle-7.4.2 디렉터리에 그래들 파일이 있는지 확인함
ls /opt/gradle/gradle-7.4.2
- 그래들에 대한 환경 변수를 설정함
- gradle.sh 파일에 GRADLE_HOME 경로를 설정함
- 그다음에는 ctrl+x 입력 후 y를 누르고 enter를 누름
sudo nano /etc/profile.d/gradle.sh
export GRADLE_HOME=/opt/gradle/gradle-7.4.2 export PATH=${GRADLE_HOME}/bin:${PATH} - chmod + x 명령어를 실행해 스크립트를 실행할 수 있도록 권한을 부여함
sudo chmod +x /etc/profile.d/gradle.sh - source 명령어를 사용해 환경 변수를 가져옴
- source 명령어는 스크립트 파일을 수정한 뒤 바로 수정된 값을 적용할 때 사용
source /etc/profile.d/gradle.sh - 그래들이 제대로 설치되었는지 그래들 버전을 표시하는 명령어로 확인함
gradle -v
- 이제 그래들을 사용하기 위해 젠킨스로 이동해 Jenkins 관리 - Tools를 클릭함
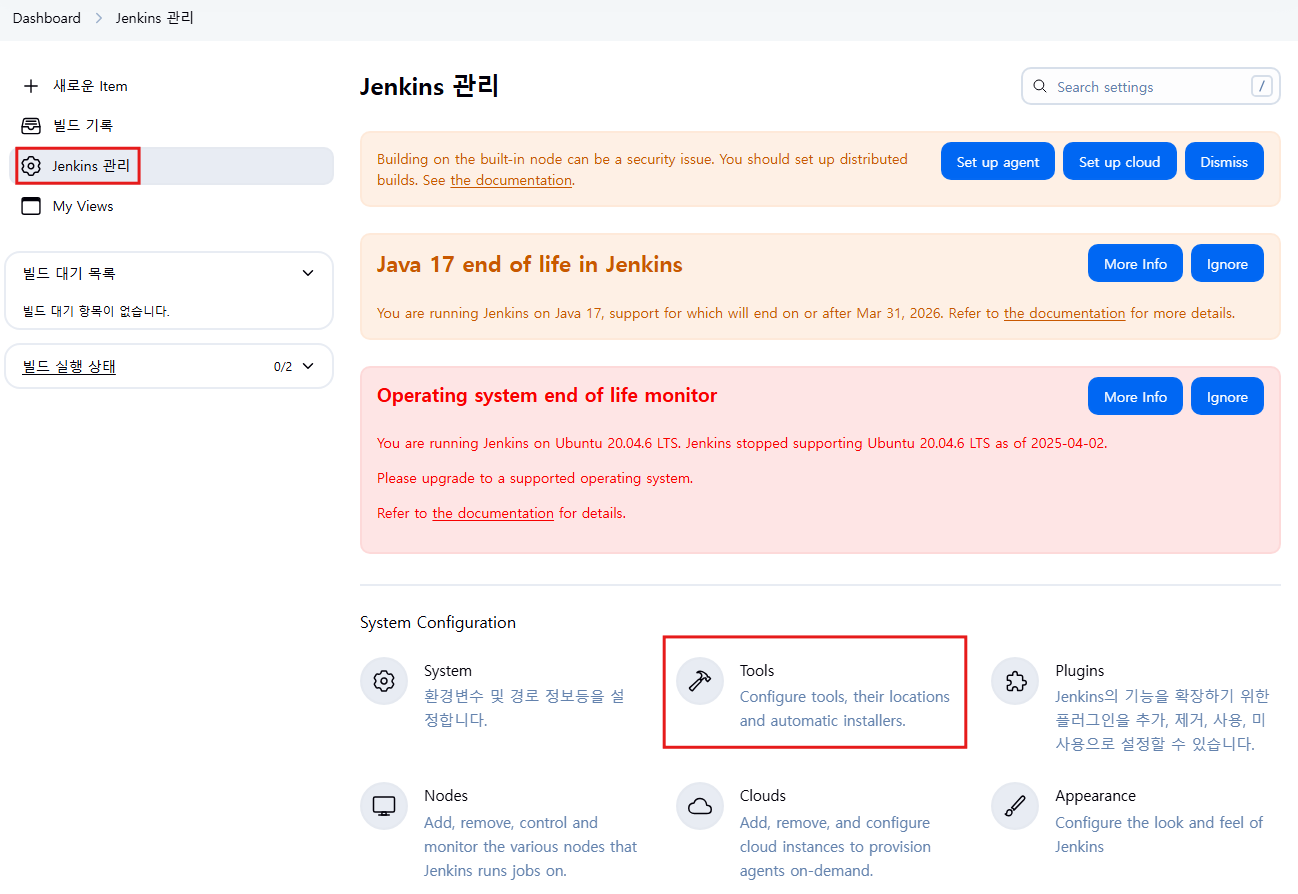
- 화면을 아래로 내려 Gradle을 찾은 후 Add Gradle을 클릭함

- 다음과 같이 입력한 후 맨 밑에 있는 Save를 클릭함
- Install automatically : 선택 해제
- name : 젠킨스 내에서 사용할 이름 설정
- GRADLE_HOME : 앞에서 PATH로 등록한 경로
- 초기 화면으로 돌아오면 다시 New Item을 클릭함
- All이라는 메뉴가 생기는데 All 메뉴 옆의 화살표를 클릭하고 앞에서 생성해둔 Jenkins_test를 클릭함

- 구성 - Build Steps으로 이동해 Add build step에서 Invoke Gradle script를 선택함

- 이제 그래들에 대해 다음과 같이 설정함
- Gradle Version : 앞에서 설정한 이름을 선택함
- Task : clean을 입력함(clean은 디스크 초기화 명령어)
- 웹훅(webhook)을 설정하기 위해 다시 깃허브로 이동해서 Settings를 클릭함
- 웹훅 : 특정 이벤트가 발생하고 나서 특정 스크립트를 실행시킬 때 사용. 따라서 다른 서비스와의 통합이나 특정 API를 호출할 때 사용함
- Webhooks 메뉴로 이동한 후 Add webhook 버튼을 클릭함
- URL(젠킨스가 실행되고 있는 노드의 IP와 포트)과 Content Type(application/json)을 선택
- Add webhook 버튼 클릭
- 입력한 IP가 공인 IP가 아니라면 생성 후 오류가 발생할 수 있음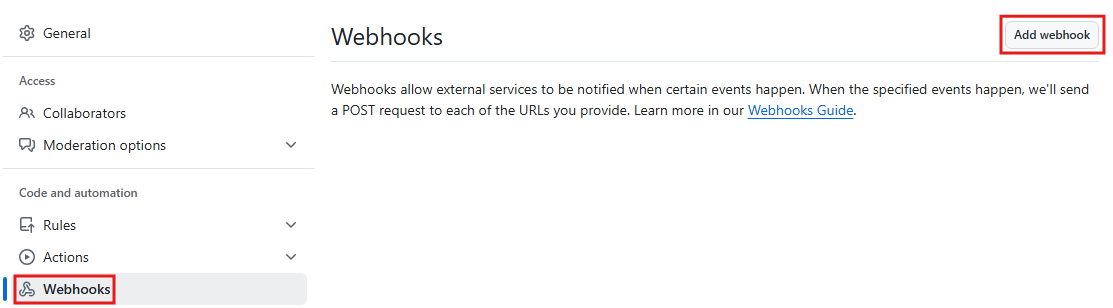

- 이후 젠킨스로 돌아와서 다음과 같이 '지금 빌드'를 클릭함
- 자동으로 빌드가 진행됨
- 깃허브에 소스 코드를 저장한 후 수정하면 자동으로 빌드가 됨
- 혹은 '지금 빌드'를 클릭해 강제로 빌드를 할 수도 있음


03. 지속적 배포 자동화 도구, ArgoCD
ArgoCD
- 깃옵스 기반의 자동화 배포 도구
- 깃옵스 리포지터리에 저장된 매니페스트가 쿠버네티스 운영 환경에도 똑같이 반영되도록 하는것
- 이미지를 배포할 때 툴(ArgoCD, Flux CD 등)이 자동으로 변경된 부분을 인식해서 쿠버네티스에 배포함
- ArgoCD의 특징
- 지정된 환경에 애플리케이션을 자동으로 배포하고 관리
- 다수의 클러스터를 단일의 환경에서 관리
- RBAC기반의 권한 부여
- 깃옵스 리포지터리를 사용하므로 백업 및 롤백 가능
- 애플리케이션 리소스의 상태 분석
ArgoCD 설치하기
- ArgoCD 설치를 위해 argocd라는 네임스페이스를 먼저 생성함
kubectl create namespace argocd
- 클러스터에 ArgoCD를 설치함
- 설치를 위해 다음 명령어를 이용하며, -f 옵션은 yaml 파일과 함께 사용할 때 사용
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
- ArgoCD를 외부에서 접속할 수 있도록 서비스의 타입을 로드밸런서(LoadBalancer)로 설정함
kubectl patch svc argocd-server -n argocd -p '{"spec": {"type" : "LoadBalancer"}}'
- API 서버와의 상호작용을 위해 ArgoCD CLI를 설치함
VERSION=$(curl --silent "https://api.github.com/repos/argoproj/argo-cd/releases/latest" \ | grep '"tag_name"' \ | sed -E 's/.*"([^"]+)".*/\1/') sudo curl -sSL -o /usr/local/bin/argocd https://github.com/argoproj/argo-cd/releases/download/$VERSION/argocd-linux-amd64 sudo chmod +x /usr/local/bin/argocd - 설치가 끝나면 ArgoCD 접속을 위해 필요한 admin 사용자의 패스워드를 확인함
- admin으로 비밀번호를 변경하는 과정을 거침
htpasswd -bnBC 12 "" admin | tr -d ':\n'
- 위 명령어로 나온 결과의 값을 복사 후 아래의 코드에 붙여넣음
kubectl -n argocd patch secret argocd-secret \ -p '{"stringData": { "admin.password": "(위의 해시 비밀번호)", "admin.passwordMtime": "'$(date +%FT%T%Z)'"}}'
- ArgoCD 서버 Pod 재시작
kubectl -n argocd delete pod -l app.kubernetes.io/name=argocd-server # Argo CD 서버 Pod 재시작 - ArgoCD에 접속할 포트 번호 확인
- http는 30456를 사용하고, https는 32490을 사용함
kubectl get svc -n argocd argocd-server
- 브라우저에서 마스터 노드의 IP에 접근함 (2가지 방법중 하나로 하면 됨)
- Hyper-V 관리자에서 master에 접속해 파이어폭스(Firefox) 브라우저에서 localhost:32490에 접근
- Hyper-V가 설치된 컴퓨터의 브라우저에서 마스터노드의 IP:32490으로 접근
- URL : https://localhost:32490
- 사용자 : admin / 패스워드 : (앞에서 설정한 패스워드)

ArgoCD 사용하기
- 리포지터리 연결 및 애플리케이션 배포 설정 확인
- 설정을 클릭 후 Repositories를 클릭함

- 리포지터리에 연결할 수 있는 방법들을 보여주는데, +CONNECT REPO를 클릭함

- 연결 방법은 HTTP/HTTPS, Repository URL에는 젠킨스에서 사용했던 깃허브 주소, username에는 깃허브에서 사용하는 사용자, password에는 깃허브 토큰을 입력한 후 상단의 connect를 클릭함

- 다음와 같이 정상적으로 연결된 화면이 나옴

- 애플리케이션을 배포하기 위해 왼쪽 메뉴의 두 번째 아이콘을 클릭한 후 New App을 클릭함

- General 항목은 다음과 같이 설정
- Application Name은 임의로 지정
- Source 지정을 위해 먼저 깃허브에 접속해 Creating a new file을 클릭함
- 입력 후에는 반드시 /를 추가해야 함
- 입력할 이름 역시 임의로 지정
- 이후 다시 argoCD로 돌아와서 Source 부분의 Path에 앞에서 지정한 Resources/App를 지정함

- Destination은 다음과 같이 설정한 후 상단의 Create를 클릭

- 다음과 같이 정상적으로 설정된 것을 확인할 수 있음
- argocd-test를 클릭함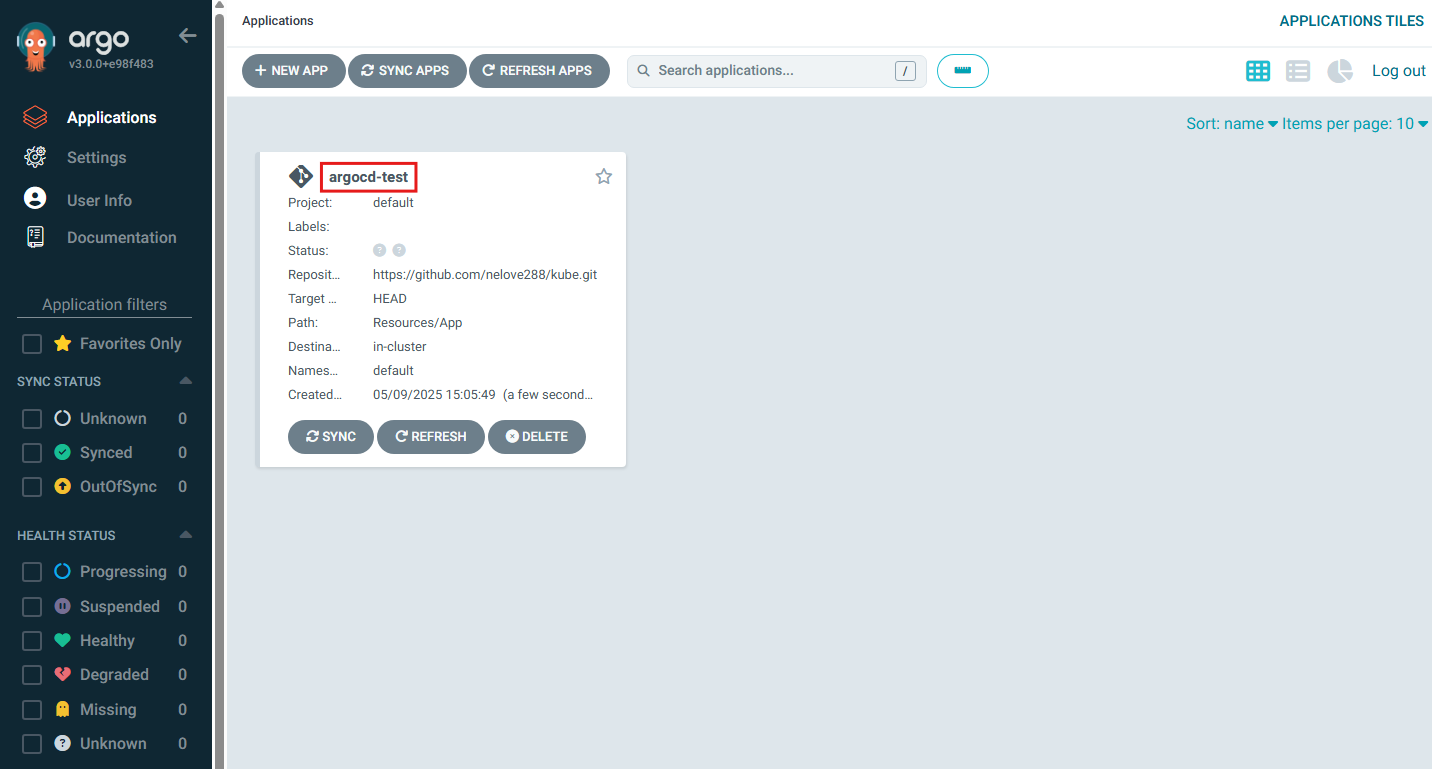
- Resources/App에 위치한 Readme.md 파일이 자동으로 동기화되어 다음 그림과 같이 현재 동기화 상태임을 확인

2. 쿠버네티스 리소스 관리
01. 쿠버네티스 모니터링
쿠버네티스 모니터링
- 쿠버네티스 환경을 안정적으로 관리하고 운영하기 위한 모니터링 방법을 살펴봄
- 쿠버네티스를 모니터링할 때 사용하는 도구는 데이터독(Datadog)과 프로메테우스(Prometheus)
- 어떤 것을 사용하느냐는 사용하려는 환경이나 사용자마다 다를 수 있음
| 구분 | 데이터독 | 프로메테우스 |
| 구축 형태 | SaaS (클라우드 형태로 구축) | 직접 구축 |
| 설치 | 간편함 | 그라파나까지 연계할 경우 상대적으로 복잡함 |
| 그래프 | 상대적으로 강력한 그래프 기능 제공 | 그래프(시각화) 취약, 그라파나와 연계해야 데이터독 수준의 그래프 기능 제공 |
| 쿠버네티스 이벤트 | 쿠버네티스 클러스터에서 발생하는 이벤트를 수집함 | 쿠버네티스 클러스터에서 발생하는 이벤트를 수집하기 위해 또 다른 솔루션이 필요함 |
| 알람 | 유형별 알람 설정에 제한적(프로메티우스의 알람 매니저가 제공하는 기능보다 제한적) | 알람 매니저(alertmanager)를 설치해야 함 |
데이터독
- 실시간 데이터 통합 플랫폼을 지향
- 클라우드 모니터링 서비스로 시작해 시스템 모니터링, 로그 관리 등의 기능을 추가하면서 종합 모니터링 플랫폼으로 성장함
- 쿠버네티스 환경뿐만 아니라 기업의 시스템에 대한 전반적인 모니터링을 제공함
- 데이터독을 쿠버네티스에 사용한다면 파드와 컨테이너 같은 쿠버네티스 클러스터의 구성 요소와 워크로드, 네트워크 트래픽 등을 모니터링할 수 있음
- 모니터링에 사용되는 메트릭 정보는 각 노드에 설치된 에이전트를 통해 수집됨
- 데이터독의 기능
- 대시보드 : 임계치를 설정해 성능에 관한 지표를 수집하고 수집된 내용을 한눈에 파악할 수 있도록 대시보드에 시각적으로 보여줌
- 시스템 : 데이터독에 등록된 노드를 포함해 기업에서 관리하는 시스템과 네트워크(트래픽 흐름)에 대한 전반적인 내용을 확인할 수 있음
- 로그 수집 : 시스템 및 애플리케이션에서 발생하는 로그를 수집함 - 모니터링에 필요한 에이전트
- 클러스터 에이전트 : 쿠버네티스 API 서버와 데이터독 에이전트(모든 워커 노드에 배포) 간의 프록시 역할을 하는 에이전트
- 데몬셋 에이전트 : 모든 워커 노드에 배포되는 데몬셋 에이전트 - 데이터독 설치하기
- https://www.datadoghq.com/ 에 접속한 후 FREE TRIAL을 클릭함
- 유료 서비스이지만 테스트 용도로 사용할 수 있는 트라이얼 버전을 제공하고 있음
- 필요한 정보를 입력한 후 Sign up을 클릭함

- 어떤 환경을 사용할지를 묻는 화면, Kubernetes를 선택하고 Next를 클릭함

- 설치를 진행할 OS에 맞게 선택함
- 오른쪽 화면에서 다음과 같이 'Install the Datadog Agent on Linux'에 나타난 명령어를 복사함
- 복사한 명령어를 마스터노드와 워커 노드에서 실행함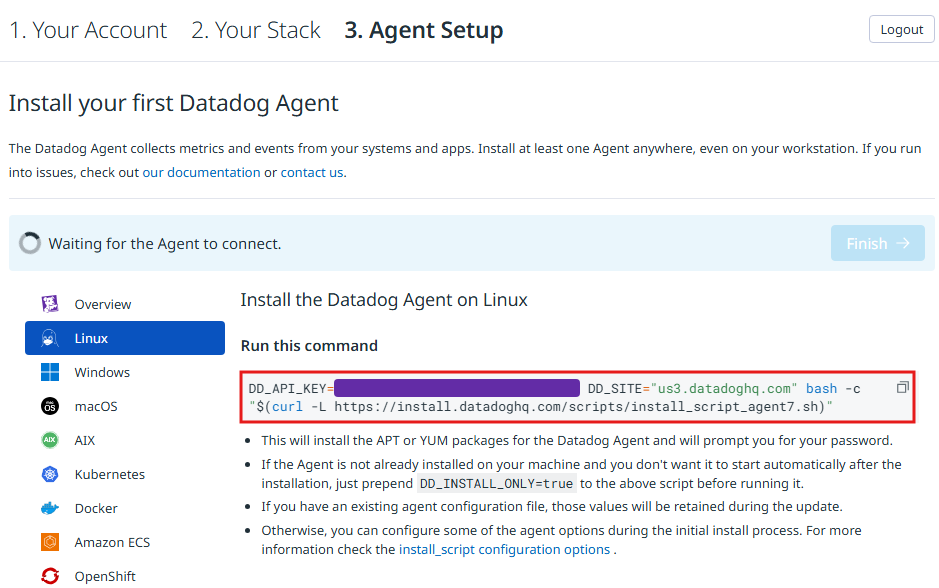
- 설치가 끝나면 데이터독 에이전트를 시작함
systemctl start datadog-agent - 다시 URL에 접속해 메인 페이지로 이동하면 노드들이 추가된 것을 확인할 수 있음

- 노드에 대한 모니터링 항목들이 수집되고, 수집된 내용을 대시보드에서 확인할 수 있음

- https://www.datadoghq.com/ 에 접속한 후 FREE TRIAL을 클릭함
프로메테우스
- 사운드클라우드(SoundCloud)에서 최초로 개발했고 현재는 CNCF(오픈소스)에 속한 모니터링 솔루션
- 기본적인 데이터 수집은 풀(가져오는 방식) 구조로 되어 있어서 프로메테우스 서버가 수집하려는 대상에서 데이터를 가져옴
- 수집된 메트릭 값을 저장하기 위한 볼륨이 필요하며, 관리자에게 알림을 발송해야 하는 상황에서는 알람 매니저(alert-manager)를 이용함
- 프로메테우스 특징
- 그라파나를 통한 시각화 지원
- 많은 시스템을 모니터링할 수 있는 다양한 플러그인 지원함
- 쿠버네티스의 모니터링 시스템으로 많이 사용됨
- 프로메테우스와 관련해 네임스페이스를 생성하는 것
- monitoring이라는 이름으로 네임스페이스를 생성함
kubectl create ns monitoring
- prometheus-cluster-role.yaml을 작성함
- 쿠버네티스의 리소스는 API를 통해 접근할 수 있지만 API를 외부에서 접근하는 것은 보안에 의해 강력히 통제됨
- 쿠버네티스 API에 접근할 수 있는 권한을 부여하기 위해 클러스터 역할을 설정하고 클러스터 역할 바인딩을 함
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus namespace: monitoring rules: - apiGroups: [""] resources: - nodes - nodes/proxy - services - endpoints - pods verbs: ["get", "list", "watch"] - apiGroups: - extensions resources: - ingresses verbs: ["get", "list", "watch"] - nonResourceURLs: ["/metrics"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: default namespace: monitoring - kubectl apply 명령어로 클러스터 역할 바인딩을 생성함
kubectl apply -f prometheus-cluster-role.yaml
- prometheus-config-map.yaml 파일 작성
- 프로메테우스에서 수집할 지표를 정의해야 함
- 환경 설정과 관련된 것으로 컨피그맵을 이용함
- 어떤 지표를 어느 주기로 수집할 것인지, 알람은 어떨 때 받을지에 대한 환경 설정 내용
apiVersion: v1 kind: ConfigMap metadata: name: prometheus-server-conf labels: name: prometheus-server-conf namespace: monitoring data: prometheus.rules: |- groups: - name: container memory alert rules: - alert: container memory usage rate is very high( > 55%) expr: sum(container_memory_working_set_bytes{pod!="", name=""})/ sum (kube_node_status_allocatable_memory_bytes) * 100 > 55 for: 1m labels: severity: fatal annotations: summary: High Memory Usage on identifier: "" description: " Memory Usage: " - name: container CPU alert rules: - alert: container CPU usage rate is very high( > 10%) expr: sum (rate (container_cpu_usage_seconds_total{pod!=""}[1m])) / sum (machine_cpu_cores) * 100 > 10 for: 1m labels: severity: fatal annotations: summary: High Cpu Usage prometheus.yml: |- global: scrape_interval: 5s evaluation_interval: 5s rule_files: - /etc/prometheus/prometheus.rules alerting: alertmanagers: - scheme: http static_configs: - targets: - "alertmanager.monitoring.svc:9093" scrape_configs: - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-nodes' scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics - job_name: 'kubernetes-pods' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'kube-state-metrics' static_configs: - targets: ['kube-state-metrics.kube-system.svc.cluster.local:8080'] - job_name: 'kubernetes-cadvisor' scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - 생성한 컨피그맵 파일을 kubectl apply 명령으로 실행함
kubectl apply -f prometheus-config-map.yaml
- prometheus-deployment.yaml 파일을 작성함
- 프로메테우스를 통해 수집한 데이터를 저장할 볼륨이 필요함
- 따라서 파드에는 메트릭 정보가 저장될 저장소를 설정해야 함
- 해당 파일에 디플로이먼트를 생성하고 해당 파드에 저장소를 연결하는 내용을 입력함
apiVersion: apps/v1 kind: Deployment metadata: name: prometheus-deployment namespace: monitoring spec: replicas: 1 selector: matchLabels: app: prometheus-server template: metadata: labels: app: prometheus-server spec: containers: - name: prometheus image: prom/prometheus:latest args: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus/" ports: - containerPort: 9090 volumeMounts: - name: prometheus-config-volume mountPath: /etc/prometheus/ - name: prometheus-storage-volume mountPath: /prometheus/ volumes: - name: prometheus-config-volume configMap: defaultMode: 420 name: prometheus-server-conf - name: prometheus-storage-volume emptyDir: {} - kubectl apply를 통한 디플로이먼트(파드)를 생성함
kubectl apply -f prometheus-deployment.yaml
- prometheus-node-exporter.yaml 파일을 생성하여 노드 내보내기에 대해 정의함
- 노드 내보내기(node exporter) : 쿠버네티스 노드에 대한 정보를 수집하는 역할을 함
- 각 노드에 하나씩 파드 형태로 존재해야 하므로 데몬셋으로 만들어야 함
- 데몬셋으로 '노드 내보내기'를 생성하고, 이것을 외부에 노출시키기 위한 서비스를 생성함
apiVersion: apps/v1 kind: DaemonSet metadata: name: node-exporter namespace: monitoring labels: k8s-app: node-exporter spec: selector: matchLabels: k8s-app: node-exporter template: metadata: labels: k8s-app: node-exporter spec: containers: - image: prom/node-exporter name: node-exporter ports: - containerPort: 9100 protocol: TCP name: http --- apiVersion: v1 kind: Service metadata: labels: k8s-app: node-exporter name: node-exporter namespace: kube-system spec: ports: - name: http port: 9100 nodePort: 31672 protocol: TCP type: NodePort selector: k8s-app: node-exporter - kubectl apply 명령어로 데몬셋과 서비스를 생성함
kubectl apply -f prometheus-node-exporter.yaml
- prometheus-svc.yaml 파일을 작성해 외부에서 프로메테우스 서비스에 접속할 수 있도록 노드포트를 사용함
- 외부에서 프로메테우스 파드에 접근하기 위한 노드포트를 정의함
- 노드포트는 30001을 사용하도록 지정함
apiVersion: v1 kind: Service metadata: name: prometheus-service namespace: monitoring annotations: prometheus.io/scrape: 'true' prometheus.io/port: '9090' spec: selector: app: prometheus-server type: NodePort ports: - port: 8080 targetPort: 9090 nodePort: 30001 - 프로메테우스 파드에 접속하기 위한 서비스를 생성함
kubectl apply -f prometheus-svc.yaml
- 외부에서 접속할 때에는 노드IP:300001을 이용해 접속함
- 현재 마스터 노드 1대, 워커 노드 1대로 구성되어 있음.
- 따라서 워커 노드 1대에 데몬셋 파드(node-exporter)가 배포되었으며, 프로메테우스 용도의 파드가 1개 실행 중
kubectl get pod -n monitoring
- 마스터 노드IP :30001로 접속함
- 접속한 화면이 아래와 같으면 프로메테우스가 정상적으로 설치된 것
* 프로메테우스는 단독으로 운영하는 것보다는 그라파나와 함께 연동해야 완벽한 모니터링을 구축할 수 있어서 보통 함께 사용함
그라파나
- 수집된 메트릭을 이용해 조회, 시각화, 경고 등의 기능을 지원함
- 프로메테우스, 엘라스틱서치(Elasticsearch), OpenTSDB 및 인플럭스 DB(InfluxDB) 같은 시계열 데이터베이스를 지원함
- 구글 스택드라이버(Google Stackdriver), 아마존 클라우드와치(Amazon Cloudwatch), 마이크로소프트 애저 같은 퍼블릭 클라우드는 물론 MySQL, Postgres 같은 SQL 데이터베이스도 지원함
- 프로메테우스에서 수집한 메트릭을 이용해 해당 데이터를 대시보드에서 시각적으로 보여주는 툴
그라파나 설치하기
- grafana.yaml 파일을 먼저 작성함
- 데이터 시각화를 표현할 대시보드 생성
- yaml 파일에서는 그라파나 이미지를 가져와서 디프로링먼트를 생성하고 이를 외부로 노출하기 위한 서비스도 함께 생성
apiVersion: apps/v1 kind: Deployment metadata: name: grafana namespace: monitoring spec: replicas: 1 selector: matchLabels: app: grafana template: metadata: name: grafana labels: app: grafana spec: containers: - name: grafana image: grafana/grafana:latest ports: - name: grafana containerPort: 3000 env: - name: GF_SERVER_HTTP_PORT value: "3000" - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL value: / --- apiVersion: v1 kind: Service metadata: name: grafana namespace: monitoring annotations: prometheus.io/scrape: 'true' prometheus.io/port: '3000' spec: selector: app: grafana type: NodePort ports: - port: 3000 targetPort: 3000 nodePort: 30004 - 디플로이먼트(파드)와 서비스를 생성함
kubectl apply -f grafana.yaml
프로메테우스와 연동하기
- 브라우저에서 IP:30004로 접속하면 그라파나 화면이 보임
- 화면에서 add your first data source를 클릭함
- Prometheus를 클릭함

- HTTP URL에 Prometheus-service의 IP를 입력하고 포트는 8080을 사용
- Prometheus-service의 IP는 kubectl get svc -n monitoring을 통해 확인함
- 마지막으로 맨아래의 Save & test를 클릭함
- 다음과 같은 화면을 볼 수 있음
대시보드 생성하기
- https://grafana.com/grafana/dashboards/로 이동함
- 다양한 유형의 모니터링 템플릿들이 있음
- 검색 부분에 Kubernetes Cluster (Prometheus)를 입력하고 결과중 첫 번째 검색 결과를 클릭함
- 이동한 화면에서 Copy ID to Clipboard를 클릭해 ID를 복사해 둠

- 그라파나 화면으로 돌아와서 왼쪽 메뉴 중 대시보드 아이콘 → New → Import 버튼을 클릭함
- 그라파나 웹페이지에서 제공하는 대시보드를 가져올 수 있음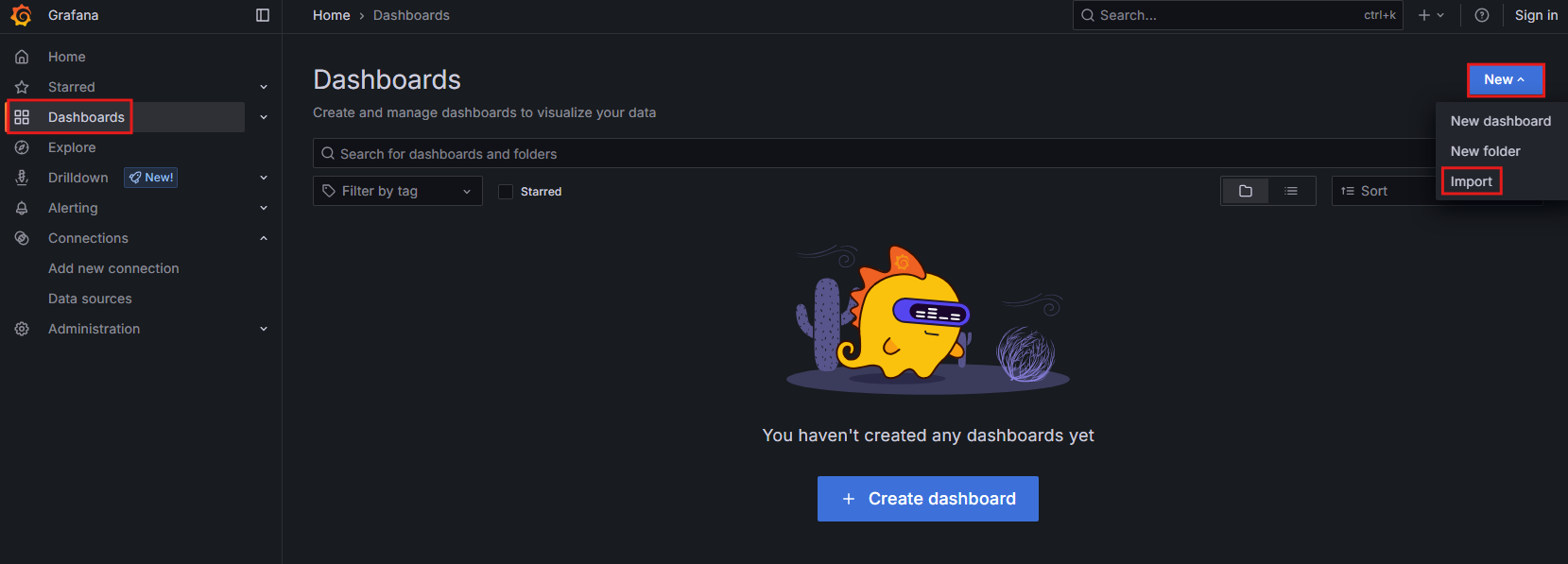
- 앞에서 복사해 둔 ID를 붙여넣기하고 Load를 클릭함

- Prometheus에 Prometheus를 선택한 후 Import를 클릭함

- 다음과 같이 모니터링 대시보드가 구성됨

02. 컨테이너 리소스 관리하기
- 하나의 노드에는 수십 개에서 수백 개의 파드가 떠 있을 수 있음
- 만약 하나의 파드에서 과도하게 자원(CPU, 메모리 등)을 사용한다면 다른 파드에 영향을 줄 수 있으므로 노드와 파드의 사용량을 지속적으로 모니터링 해야함
- 파드 자원의 사용률이 낮다면 회수하고, 사용률이 높다면 추가적인 자원을 할당하거나 파드를 늘려야함
- 가장 효율적으로 자원을 관리할 수 있는 LimitRange와 오토스케일링 방법에 대해 배움
LimitRange 사용하기
- 파드(컨테이너)에서 사용할 수 있는 리소스(자원)의 사용률을 제한하는 것을 의미함
- CPU가 어느 한계(ex: 80%)에 다다르면 더 이상 사용률이 증가하지 못하도록 설정함
- set-limit-range.yaml라는 파일을 작성함
- 생성한 파일에 CPU에 대한 최소값과 최대값을 지정하는 내용을 입력함
apiVersion: v1 kind: LimitRange metadata: name: set-limit-range spec: limits: - max: cpu: "800m" min: cpu: "200m" type: Container - limitrange를 생성하고, 상태를 확인함
- CPU의 min과 max가 각각 0.2CPU, 0.8CPU로 설정되어 있음
- 1밀리코어(milicore)는 CPU의 1/1000을 의미하므로 800밀리코어는 0.8 코어(core)를 의미함
kubectl apply -f set-limit-range.yaml
kubectl get limitrange kubectl describe limitrange set-limit-range
- pod-with-cpu-range.yaml 파일을 작성함
- CPU 요청량(노드에 요청하는 CPU 사이즈)과 최대 사이즈를 지정하기 위함
- CPU 요청량은 500밀리코어, 최대 사이즈는 800밀리코어를 사용하도록 설정함
apiVersion: v1 kind: Pod metadata: name: pod-with-cpu-range spec: containers: - name: pod-with-cpu-range image: nginx resources: limits: cpu: "800m" requests: cpu: "500m" - CPU 사용이 제한된 파드를 생성함
kubectl create -f pod-with-cpu-range.yaml
- 파드의 상태를 확인함
- CPU 요청량은 500 밀리코어, 최대 사이즈는 800밀리코어로 설정된 것을 확인할 수 있음
- 하지만 이렇게 자원 사용량에 제한을 두면 서비스 속도에 문제가 발생할 수 있음
- 서비스에 어떠한 영향도 주지 않으면서 빠른 속도를 보장하기 위해 사용하는 것이 오토스케일링
kubectl get pods kubectl describe pod pod-with-cpu-range
- requests : 적어도 지정된 만큼의 자원은 컨테이너에서 사용할 수 있도록 보장함
- limits : 유휴 자원이 있다면 최대 지정된 만큼의 자원까지 컨테이너가 사용할 수 있음
오토스케일링
- 할당된 파드의 자원 사용률이 너무 낮거나 높을 때 리소스의 크기를 조정하는 것을 의미함
- 시스템 스스로 자원 사용률을 감지해 자동으로 파드를 늘려주거나 줄여줄 필요가 있음
- 최대 몇 대까지 늘려줄 수 있는지 지정할 수 있는데, 이것을 최대 사이즈라고 함
- 최소 사이즈와 최대 사이즈를 지정해 늘리고 줄이는 파드의 개수를 조정할 수 있음
- 오토스케일링의 동작 방식
- 메트릭스 서버에 각 파드에서 사용 중인 자원(ex: CPU, 메모리)이 어느 정도인지 질의함
- 반환값에 따라 몇 개의 파드를 늘려야 하는지 수평적 파드 오토스케일링(horizontal pod autoscaler)에서 계산함
- 계산된 파드의 개수만큼 애플리케이션 파드를 늘림
- 메트릭 서버는 자동으로 설치되지 않아서 수동으로 설치함
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
- 설치가 완료되었다면 메트릭 디플로이먼트 설정을 변경함
- 변경하지 않으면 메트릭 서버가 작동하지 않음
kubectl edit deployments.apps -n kube-system metrics-server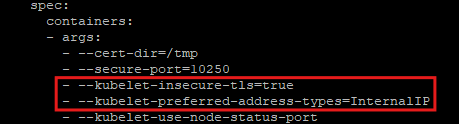
- API 서버(kube-apiserver)의 설정을 변경함
- 이 설정도 변경하지 않으면 메트릭 서버가 작동하지 않음
vi /etc/kubernetes/manifests/kube-apiserver.yaml
- php-apache.yaml라는 파일을 작성함
- 오토스케일링 테스트를 위한 디플로이먼트와 서비스 생성을 위함
- php-apache라는 이름의 디플로이먼트를 생성할 때 사용할 수 있는 CPU 범위(최대 500m)를 지정
apiVersion: apps/v1 kind: Deployment metadata: name: php-apache spec: selector: matchLabels: run: php-apache replicas: 1 template: metadata: labels: run: php-apache spec: containers: - name: php-apache image: k8s.gcr.io/hpa-example ports: - containerPort: 80 resources: limits: cpu: 500m requests: cpu: 200m --- apiVersion: v1 kind: Service metadata: name: php-apache labels: run: php-apache spec: ports: - port: 80 selector: run: php-apache - kubectl apply 명령어로 디플로이먼트와 서비스를 생성함
kubectl apply -f php-apache.yaml
- 오토스케일링을 설정함
- 파드의 개수를 늘리거나 줄이도록 설정함
- CPU 사용률이 50%를 넘긴다면 파드의 개수를 최대 10개까지 늘릴 수 있음
- CPU 사용률이 50% 이하라면 파드의 개수를 줄일 수 있지만 최소 1개는 유지하도록 설정함
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
- 어떤 변화도 주지 않았을 때의 CPU 사용률은 0%임
- 현재의 사용률이 <unknown>으로 표시된다면 2~3분 후에 다시 실행하면 됨
kubectl get hpa
- 각 파드에 대한 자원 사용률과 현재 몇 개의 파드가 실행 중인지도 확인함
- 현재 한 개의 파드만 실행 중임
kubectl top pods kubectl get deployment php-apache
- 실제로 부하에 따라 파드의 개수가 변하는지 확인하기 위해 강제로 부하를 높임
- 3~5분 정도 후에 실행하면 결과를 눈으로 확인할 수 있음
- 이후 ctrl + c를 눌러 빠져나옴
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
- 실제로 CPU에 변화가 있는지 확인하고 파드의 개수를 확인함
- CPU 부하는 153%까지 증가함
- 파드는 7개로 증가함
kubectl get hpa kubectl get deployment php-apache
'개인 공부 > 쿠버네티스' 카테고리의 다른 글
| [쿠버네티스] VMware를 이용한 쿠버네티스 구축&배포 프로젝트 - ② (0) | 2025.05.21 |
|---|---|
| [쿠버네티스] VMware를 이용한 쿠버네티스 구축&배포 프로젝트 - ① (2) | 2025.05.20 |
| [쿠버네티스] PART2. 쿠버네티스 기본 사용법 배우기 - ② (0) | 2025.04.18 |
| [쿠버네티스] PART2. 쿠버네티스 기본 사용법 배우기 - ① (1) | 2025.04.17 |
| [쿠버네티스] PART1. 쿠버네티스 첫걸음 (0) | 2025.04.09 |



