
- Database_Design
- Univ._Study
- datastructure
- 티스토리챌린지
- Personal_Study
- Kubernetes
- c++
- Java
- 오블완
- 2023_1st_Semester
- 자격증
- Unix_System
- Baekjoon
- study
- Linux
- programmers
- cloud_computing
- codingTest
- Python
- Android
- SingleProject
- C
- Image_classification
- kubeflow
- Operating_System
- 리눅스마스터2급
- app
- Artificial_Intelligence
- tensorflow
- Algorithm
코딩 기록 저장소
[자료구조] 포인터와 연결리스트 본문
1. 포인터
- 컴퓨터는 메모리란 저장 공간을 사용하고, 모든 메모리는 주소를 가짐.
- 변수나 배열은 메모리의 어떤 위치에 저장됨.
- 만약 주소를 알면 거기에 저장된 변수 값을 참조할 수 있음.
- 포인터 변수, 또는 포인터는 이러한 메모리의 주소를 저장하기 위한 변수
포인터 선언
- 포인터도 변수이므로 일반 변수와 같이 사용하기 전에 먼저 선언되어야 함.
- 항상 어떤 자료형의 변수를 그리킴. 가리키는 자료형을 먼저 쓰고 *를 붙인 다음 변수 이름을 씀.
- *는 자료형이나 변수쪽에 모두 붙일 수 있음.
int* pi;
float *pf;
int *a,*b,*c;
- 포인터는 사용할 때 반드시 초기화 해야함.
- 포인터 p는 마지막 문장과 같이 주소 추출 연산자 &를 사용해 구한 변수 a의 주소를 값으로 갖게 됨.
int a = 10;
int *p;
p = &a;
포인터의 활용
- 포인터가 가리키는 메모리의 내용을 추출하거나 변경하려면 역참조 연산자 *를 사용함.
*p = 15; // a = 15와 같음
- 곱셈 기호 *의 여러 가지 사용 방법
1. mul = a * b; // 곱셈 연산자로 사용된 *
2. int *p; // 포인터 선언에 사용된 *
3. *p = 30; // 포인터의 역참조 연산자로 사용된 *
- 비트단위 AND 연산자 &의 여러 가지 사용 방법
1. c = a & b; // 비트단위 AND 연산자로 사용된 &
2. p = &a; // 변수의 주소 추출 연산자로 사용된 &
이중 포인터
- 어떤 포인터가 다른 포인터를 가리킬 때 사용함.
- 일반 포인터와 비슷함. 이름과 주소를 갖고, 어떤 포인터 변수가 저장된 주소를 값으로 가짐.
int a = 10;
int* p = &a;
int** pp =&p;
포인터 연산
- 배열 A가 존재하고 포인터 p가 A[2]를 가리키고 있을때, p-1은 p가 가리키는 객체 하나 앞에 있는 객체를 가리키고, p+1은 p가 가리키는 객체 하나 뒤에 있는 객체를 가리킴.
① p : 포인터
② *p : 포인터가 가리키는 값
③ *p++ : 포인터가 가리키는 값을 가져온 다음, 포인터를 한 칸 증가
④ *p-- : 포인터가 가리키는 값을 가져온 다음, 포인터를 한 칸 감소
⑤ (*p)++ : 포인터가 가리키는 값을 증가시킴.
포인터와 배열
- 배열은 포인터와 밀접한 관계를 가집.
- 배열 이름은 첫 번째 배열 원소의 주소와 같음.
- 포인터에 인덱스 연산자를 적용해 배열과 같이 사용할 수 있음.
int A[5], *p, i = 10;
p = A;
p[3] = 20;
A = &i; // 불가능
포인터와 구조체
- 포인터는 구조체를 가리킬 수도 있음.
- 멤버를 선택할 때 구조체는 '.'을 사용하지만, 포인터는 '->'연산자를 사용함.
typedef struct {
int a;
int b;
}A;
A a;
A* p;
p = &a;
a.a = 10;
p-> b = 30;
자체 참조 구조체
- 멤버 중에 자기 자신을 가리키는 포인터가 한 개 이상 존재하는 특별한 구조체를 말함.
- 자체 참조 구조체는 연결 리스트나 트리, 그래프 등에서 매우 광범위하게 사용됨.
ex) 연결 리스트에서 사용되는 노드 구조체의 예
typedef struct ListNode {
char data[10];
struct ListNode* link;
}Node;
포인터 사용시 주의점
- 포인터가 어떤 값을 가리키고 있지 않을 때는 NULL로 설정하는 것이 좋음.
- 초기화가 안 된 포인터 변수가 가리키는 곳에 자료를 저장하면 안 됨.
- 자료형이 다른 포인터 사이의 변환에는 명시적인 형 변환을 사용함.
2. 동적 메모리 할당
- 프로그램에서 사용되는 변수나 객체들은 모두 자신만의 메모리를 가짐.
정적 메모리 할당
- 필요한 메모리의 크기가 프로그램이 컴파일 될 때 결정되고 프로그램의 실행 중에 크기를 변경할 수 없음.
- 생성과 제거가 자동으로 이루어져 프로그램 개발자가 신경 쓸 필요가 없음.
- 변수를 선언만 하면 자동으로 메모리가 할당되고 해당 프로그램 블록이 끝나면 자동으로 제거됨.
- 더 큰 입력이 들어오면 처리하지 못하고, 더 작은 입력이 들어오면 메모리 공간이 낭비됨.
int a;
int* b;
int C[10];
동적 메모리 할당
- 동적 메모리 할당 라이브러리 함수를 사용해 메모리를 생성하고 해제해야함.
- 프로그램 실행 중 필요한 메모리의 크기를 결정하고 시스템으로부터 할당받아서 사용할 수 있음. 사용하다 필요없으면 해제함.
- 메모리 효율적으로 사용 가능하지만 번거로움이 있음.
동적 메모리 할당 라이브러리 함수
- 동적으로 메모리를 할당하여 주소를 반환하는 함수
void* malloc(int size)
void* calloc(int num, int size)
//동적으로 해제하는 함수
void free(void* ptr)- malloc() 함수 : size 크기의 메모리 블록을 할당하고, 이 메모리 블록의 시작 주소를 반환함. 이때 단위는 바이트임.
- calloc() 함수 : 배열 형식의 메모리를 할당함. 배열 요소의 크기는 size 바이트이고 개수는 num이 됨.(0으로 초기화됨)
- 적절한 자료형으로 형변환시켜서 사용함.
int* pi = (int*)malloc(sizeof(int));- free() 함수 : 동적으로 할당되었던 메모리 블록을 시스템에 반납함. ptr은 할당되었던 메모리 블록을 가리키는 주소값.
- 자료형 명시하지 않음.
3. 연결 리스트
- 스택과 큐 등의 자료구조를 배열 대신 연결된 표현을 사용함.
- 연결된 표현은 데이터와 링크로 구성되어 있고 링크가 노드들을 연결하는 역할을 함.
- 용량이 고정되지 않으므로 연결된 표현은 여러 가지 자료구조를 구현하는데 효과적임.
연결된 표현의 특징
- 데이터를 한군데 모아두는 것을 포기함.
- 데이터들은 메인 메모리상의 어디에나 흩어져서 존재할 수 있음.
- 순서를 유지하기 위해 각각의 데이터는 다음 데이터를 가리키는 줄을 가짐.
- 첫 데이터에서부터 순서대로 줄을 따라가면 모든 데이터를 방문할 수 있음.
=> 이런식으로 흩어져있는 데이터를 연결하여 묶는 방법을 연결 리스트라고함.
연결 리스트의 장점
- 크기가 고정되지 않음.
- 중간에 자료 삽입이 용이함.
- 삭제연산도 용이함.
- 데이터 저장을 위한 메모리를 공간이 필요할 때마다 동적으로 만들어 쉽게 추가할 수 있음.
- 하지만 배열에 비해 구현이 어렵고, 오류가 발생하기 쉬운 단점이 존재함.
연결리스트의 구조
노드
- 연결리스트는 노드들의 집합이며, 데이터를 저장하고 서로 연결되어 있음.
- 데이터 필드와 링크 필드로 구성되어 있음.
- 데이터 필드 : 저장할 데이터가 들어감.
- 링크 필드 : 다른 노드의 주소를 저장하는 포인터 변수가 있음.

헤드 포인터
- 연결 리스트는 첫 번째 노드를 알면 링크로 모든 노드에 순차적으로 접근할 수 있음.
- 연결 리스트에서 첫 번째 노드의 주소를 저장하는 포인터를 헤드 포인터라고 함.
- 마지막 노드는 더 이상 연결할 노드가 없는데, 링크 필드의 값을 NULL로 설정하여 마지막임을 표현함.

연결 리스트의 특징
- 노드들은 메모리의 어느 곳에나 위치할 수 있음. 노드들의 주소가 연결 리스트 상의 순서와 동일하지 않음.
- 연속적인 기억공간이 없어도 데이터를 저장하는 것이 가능하고 미리 공간을 확보할 필요도 없음. 필요할 때마다 동적으로 노드를 생성해 연결하기 때문.
- 링크 필드를 위한 추가 공간이 필요함.
- 연산의 구현이나 사용 방법이 배열에 비해 복잡함.
- 동적 할당, 해제가 빈번하게 일어나면 메모리 관리를 위한 처리 시간이 길어져 프로그램이 느려질 수도 있음.
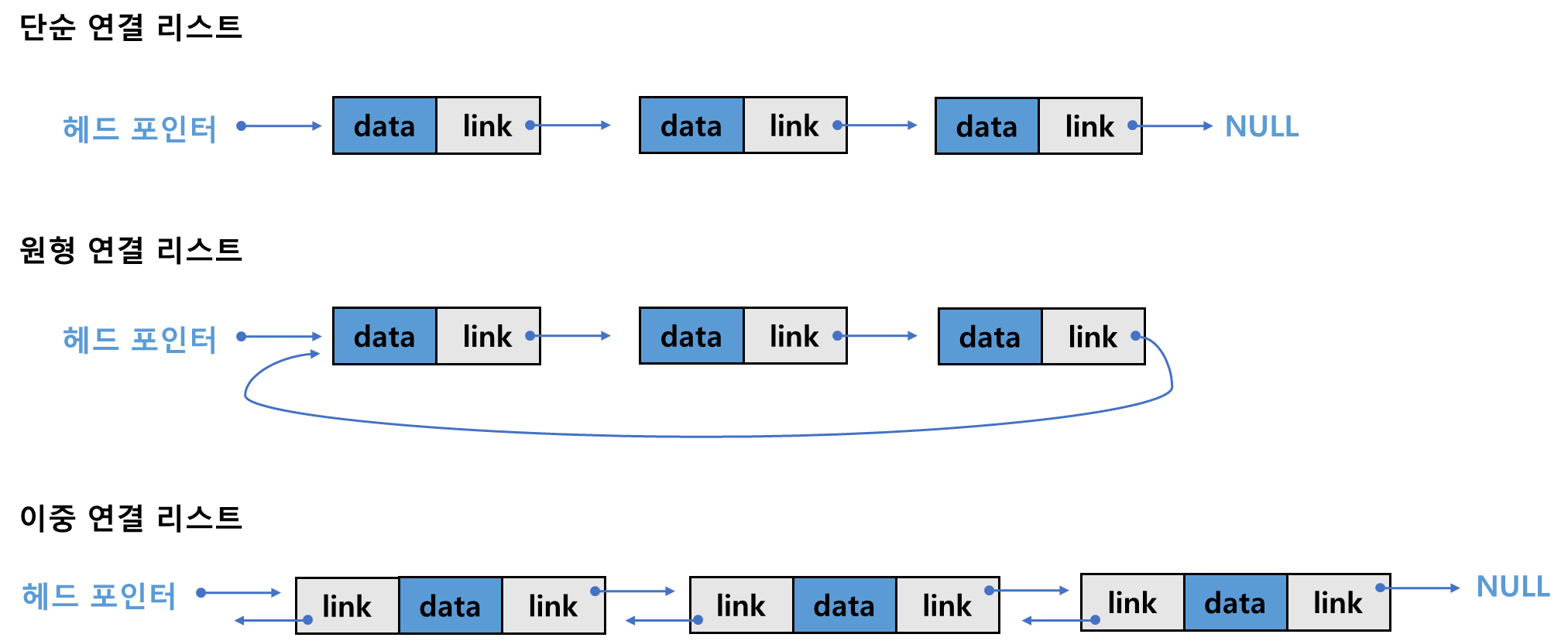
연결리스트의 종류
단순 연결 리스트
- 하나의 방향으로만 연결되어 있음.
- 맨 마지막 노드의 링크 필드는 NULL값을 가짐.
원형 연결 리스트
- 단순 연결 리스트와 같지만 맨 마지막 노드의 링크 값이 다시 첫 번째 노드를 가리킴.
이중 연결 리스트
- 각 노드마다 링크 필드, 즉 포인터가 2개씩 존재함. 각각의 노드는 선행 노드, 후속 노드를 모두 가리킴.
4. 포인터의 응용 : 연결리스트로 구현한 스택
연결된 스택의 구조
- 연결리스트로 구현한 스택은 요소를 한번에 할당하지 않고 필요할 때 마다 하나씩 동적으로 할당함. 연결된 스택에서는 노드 구조체를 추가로 정의해야함.
typedef int Element;
typedef struct LinkedNode {
Element data;
struct LinkedNode* link;
}Node;- 배열의 인덱스를 나타내던 top은 이제 포인터가 됨.
- 스택에서 top은 헤드 포인터임.

연결된 스택의 연산
- 연결된 스택에서 공백상태는 헤드 포인터 top이 NULL값을 갖는 경우.
- 스택의 초기화는 공백상태로 만드는 것이므로 top에 NULL을 복사하면 됨.
삽입 연산
1. p노드 링크필드가 기존의 top이 가리키는 노드를 가리키도록 함 : p->link = top;
2. 헤더 포인터 top이 p노드를 가리키도록 함 : top = p;

void push(Element e)
{
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
p->link = top;
top = p;
}
삭제 연산
1. 포인터 변수 p가 기존의 top이 가리키던 노드를 가리키도록 함 : p = top;
2. 헤더 포인터 top이 다음 노드를 가리키도록 함 : top = p->next;
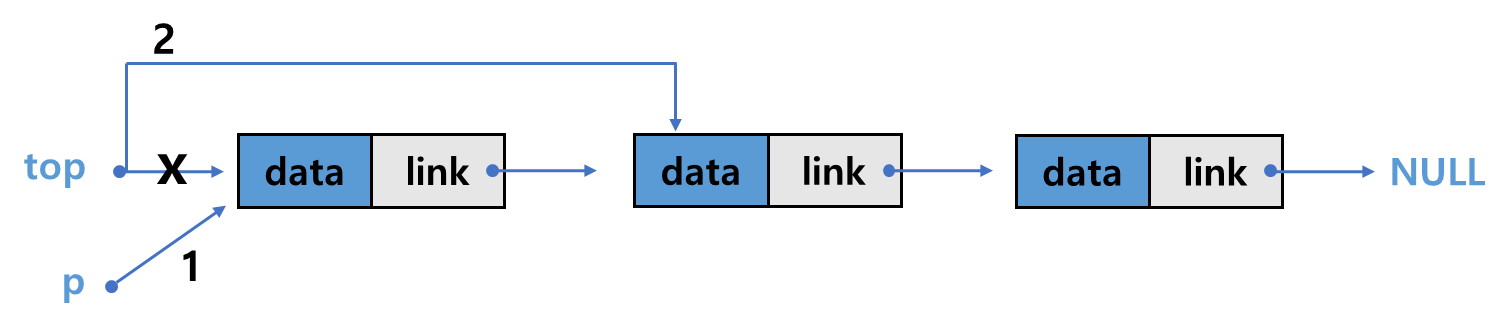
Element pop() {
Node* p;
Element e;
if (is_empty())
error("스택 공백 에러");
p = top;
top = p->link;
e = p->data;
free(p);
return e;
}
기타 연산들
1. top의 항목 pop()하지 않고 반환하는 함수
Element peek()
{
if (is_empty())
error("스택 공백 에러");
return top->data;
}2. 남은 노드 전부 해제하는 함수
void destroy_stack()
{
while (is_empty() == 0)
pop();
}3. 스택의 크기를 반환하는 함수
int size() {
int count = 0;
for (Node* p = top; p != NULL; p->link) count++;
return count;
}
전체 프로그램(int 스택) 구현 결과 및 코드

코드 보기
#include <stdio.h>
#include <stdlib.h>
typedef int Element;
typedef struct LinkedNode {
Element data;
struct LinkedNode* link;
}Node;
Node* top = NULL;
void error(char* str)
{
fprintf(stderr, "%s\n", str);
exit(1);
}
int is_empty() { return top == NULL; }
void init_stack() { top = NULL; }
void push(Element e)
{
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
p->link = top;
top = p;
}
Element pop() {
Node* p;
Element e;
if (is_empty())
error("스택 공백 에러");
p = top;
top = p->link;
e = p->data;
free(p);
return e;
}
Element peek()
{
if (is_empty())
error("스택 공백 에러");
return top->data;
}
void destroy_stack()
{
while (is_empty() == 0)
pop();
}
int size() {
Node* p;
int count = 0;
for (p = top; p != NULL; p = p->link)
count++;
return count;
}
void print_stack(char* msg)
{
Node *p;
printf("%s[%2d]= ", msg, size());
for (p = top; p != NULL; p = p->link)
printf("%2d ", p->data);
printf("\n");
}
int main() {
init_stack();
for (int i = 1; i < 10; i++)
push(i);
print_stack("연결된스택 push 9회");
printf("\tpop() --> %d\n", pop());
printf("\tpop() --> %d\n", pop());
printf("\tpop() --> %d\n", pop());
print_stack("연결된 스택 pop 3회");
destroy_stack();
print_stack("연결된 스택 destroy");
return 0;
}
5. 포인터의 응용 : 연결리스트로 구현한 큐
연결된 큐의 구조
- 연결리스트로 구현한 큐도 요소를 한번에 할당하지 않고 필요할 때 마다 하나씩 동적으로 할당하여 크기가 제한되지 않고 필요한 메모리만 사용함.
- 코드가 더 복잡하고 링크 필드 때문에 메모리 공간을 조금 더 사용함.
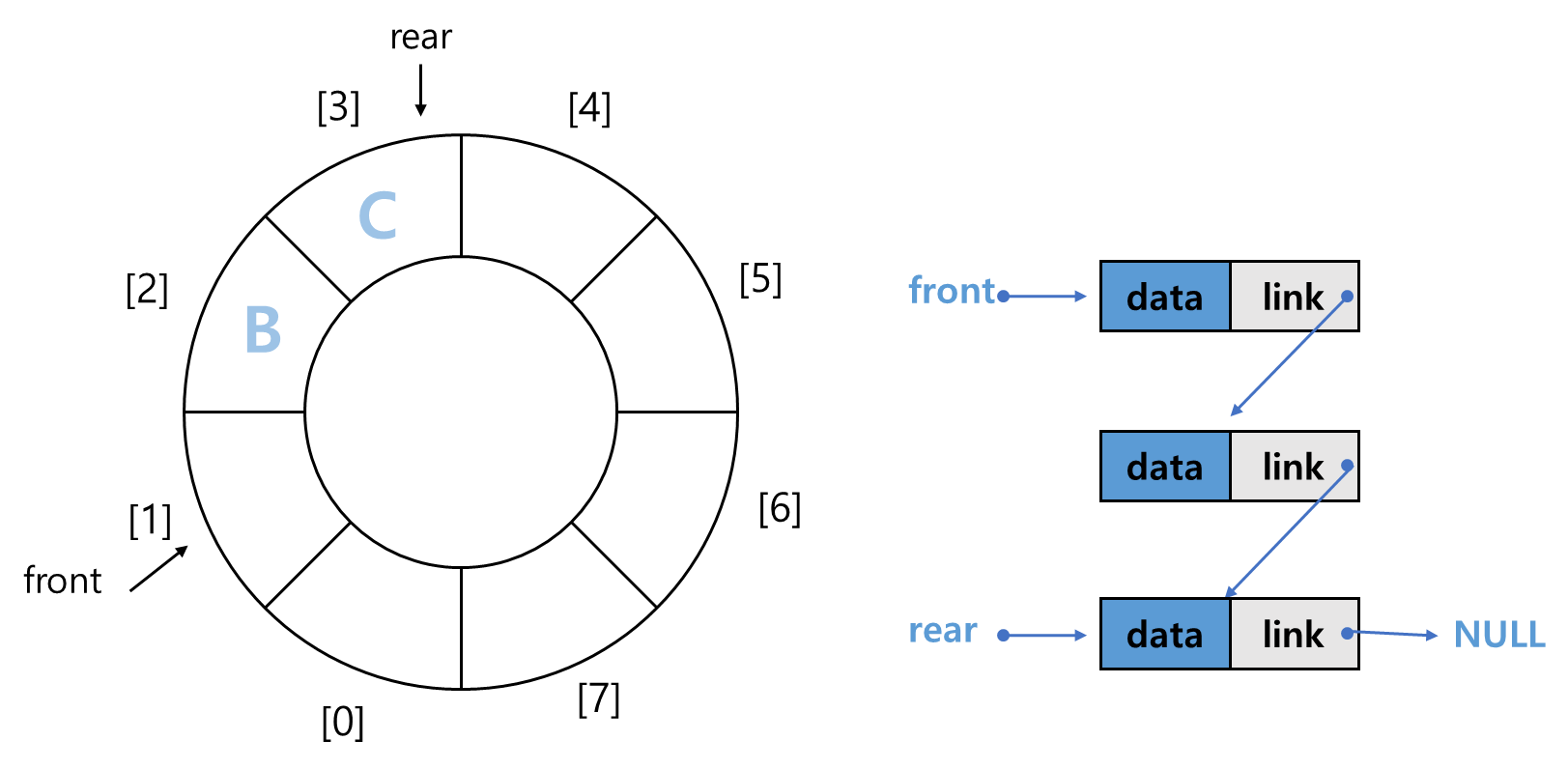
Node* front = NULL;
Node* rear = NULL;- 큐를 위한 데이터는 front와 rear임.
- front와 rear은 선언하면서 NULL로 초기화함.
연결된 큐의 연산
- 연결된 큐에서 공백상태는 front와 rear가 NULL인 경우임
- 큐의 초기화는 공백상태로 만드는 것이므로 front와 rear를 NULL로 설정하면 됨.
삽입 연산
- 연결 리스트의 후단(rear)에 새로운 노드를 추가하면 됨.
- 만약 큐가 공백상태라면 front와 rear 모두 새로운 노드 p를 가리키도록 하면 됨.
- 공백상태가 아니라면 rear만 변경됨.
1. rear가 가리키는 노드가 새로운 노드를 가리키도록 함 : rear->link = p;
2. rear가 새로운 노드를 가리키도록 함 : rear = p;
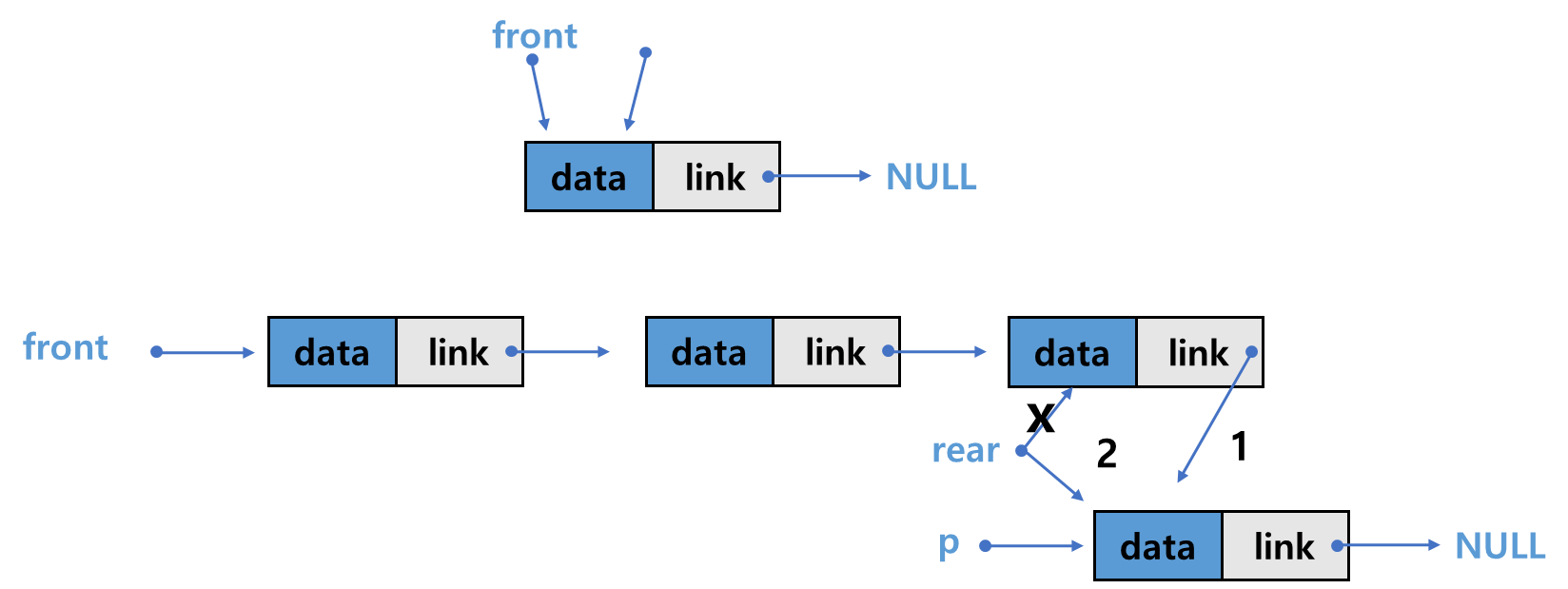
void enqueue(Element e)
{
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
p->link = NULL;
if (is_empty()) {
front = p;
rear = p;
}
else {
rear->link = p;
rear = p;
}
}
삭제 연산
- 연결 리스트의 전단에서 노드를 꺼내오면 됨.
- 공백상태인가 검사하여 공백이면 오류로 메시지를 출력하고 종료함.
- 공백상태가 아니라면 임시 포인터 p를 이용하여 처리함.
- 노드가 하나 뿐이면 front가 NULL이 되는데, 이 경우 rear도 NULL로 만들어주어야 함.
1. front가 가리키는 노드를 p가 가리키도록 함 : p = front;
2. front가 다음 노드를 가리키도록 함 : front = p->link;
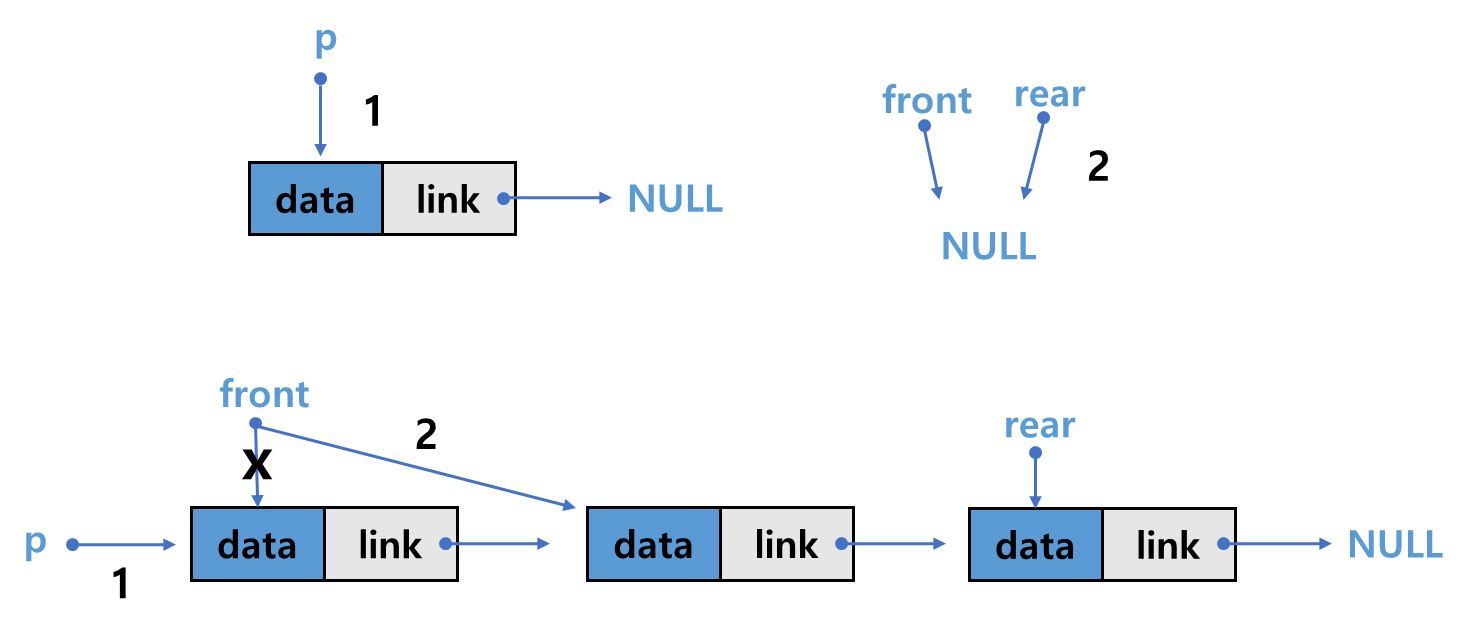
Element dequeue() {
Node* p;
Element e;
if (is_empty())
error("큐 공백 에러");
p = front;
front = front->link;
if (front == NULL)
rear = NULL;
e = p->data;
free(p);
return e;
}
전체 프로그램(int 큐) 구현 결과 및 코드
코드 보기
#include <stdio.h>
#include <stdlib.h>
typedef int Element;
typedef struct LinkedNode {
Element data;
struct LinkedNode* link;
}Node;
Node* front = NULL;
Node* rear = NULL;
void error(char* str)
{
fprintf(stderr, "%s\n", str);
exit(1);
}
int is_empty() { return front == NULL; }
void init_queue() { front = NULL; rear = NULL; }
void enqueue(Element e)
{
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
p->link = NULL;
if (is_empty()) {
front = p;
rear = p;
}
else {
rear->link = p;
rear = p;
}
}
Element dequeue() {
Node* p;
Element e;
if (is_empty())
error("큐 공백 에러");
p = front;
front = front->link;
if (front == NULL)
rear = NULL;
e = p->data;
free(p);
return e;
}
Element peek()
{
if (is_empty())
error("큐 공백 에러");
return front->data;
}
void destroy_queue()
{
while (is_empty() == 0)
dequeue();
}
int size() {
Node* p;
int count = 0;
for (p = front; p != NULL; p = p->link)
count++;
return count;
}
void print_queue(char* msg)
{
Node* p;
printf("%s[%2d]= ", msg, size());
for (p = front; p != NULL; p = p->link)
printf("%2d ", p->data);
printf("\n");
}
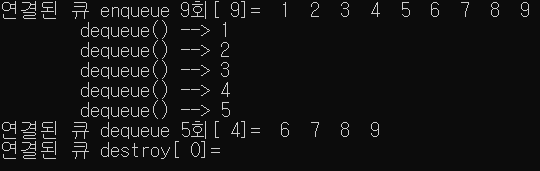
int main() {
init_queue();
for (int i = 1; i < 10; i++)
enqueue(i);
print_queue("연결된 큐 enqueue 9회");
printf("\tdequeue() --> %d\n", dequeue());
printf("\tdequeue() --> %d\n", dequeue());
printf("\tdequeue() --> %d\n", dequeue());
printf("\tdequeue() --> %d\n", dequeue());
printf("\tdequeue() --> %d\n", dequeue());
print_queue("연결된 큐 dequeue 5회");
destroy_queue();
print_queue("연결된 큐 destroy");
return 0;
}'개인 공부 > 자료구조' 카테고리의 다른 글
| [자료구조] 큐 (0) | 2023.01.25 |
|---|---|
| [자료구조] 스택 (0) | 2023.01.10 |
| [자료구조] 배열과 구조체 (0) | 2023.01.10 |
| [자료구조] 자료구조와 알고리즘 (1) | 2023.01.09 |



