
- Univ._Study
- 자격증
- programmers
- Linux
- Baekjoon
- datastructure
- Algorithm
- cloud_computing
- app
- tensorflow
- Artificial_Intelligence
- c++
- 2023_1st_Semester
- Operating_System
- 티스토리챌린지
- study
- 오블완
- C
- Image_classification
- Unix_System
- kubeflow
- 리눅스마스터2급
- Android
- SingleProject
- Python
- codingTest
- Database_Design
- Kubernetes
- Java
- Personal_Study
코딩 기록 저장소
[알고리즘] 그래프 본문
1. 그래프
- 그래프는 현상이나 사물을 정점과 간선으로 표현하는 것.
- 정점은 대상이나 개체를 나타내고, 간선은 이들 간의 관계를 나타냄.
- 방향을 가진 간선으로 그래프를 나타내면, 방향을 가진 그래프 또는 유향 그래프라고 함.
- 반면, 간선의 방향이 없는 그래프를 무향 그래프 또는 무방향 그래프라고 함.
- n개의 정점 집합 V와 이들 간에 존재하는 간선의 집합 E로 구성된 그래프 G를 보통 G=(V,E)로 표시함.

2. 그래프의 표현
- 크게 행렬을 이용하는 방법과 리스트를 이용하는 방법이 있음
인접 행렬을 이용한 방법
- 행렬 표현법은 이해하기 쉽고 간선의 존재 여부를 즉각 알 수 있다는 장점이 있음.
- 정점 i와 정점 j의 인접 여부는 행렬의 (i, j) 원소나 (j, i) 원소의 값만 보면 알 수 있기 때문.
- 대신 n × n 행렬이 필요하므로 n²에 비례하는 공간이 필요함.
- 행렬의 준비 과정에서 행렬의 모든 원소를 채우는 데만 n²에 비례하는 시간이 듦.
- 그러므로 O(n²) 미만의 시간이 소요되는 알고리즘이 필요한 경우에 행렬 표현법을 사용하면 행렬의 준비 과정에서만 Θ(n²)의 시간을 소모해버려 적절하지 않음.
- 간선의 밀도가 아주 높은 그래프에서는 인접 행렬 표현이 적합함.
1. 단순 관계 그래프
- 그래프 G=(V,E)에서 정점의 총수가 n이라 하면, 우선 n × n 행렬을 준비하고, 정점 i와 정점 j 간에 간선이 있으면 행렬의 (i,j) 원소와 (j,i) 원소의 값을 1로 할당함.
- 간선으로 연결된 두 정점은 인접하다고 함.
- 이런식으로 모든 간선에 대해서 행렬의 해당 원소에 1을 할당하고, 나머지 원소에는 0을 할당함.
- 간선의 밀도가 높은 그래프에 적합함.

2. 가중치가 있는 그래프
- 행렬의 각 원소에 1 대신 가중치를 저장함.

3. 유향 그래프
- 간선이 방향을 가지므로 인접 행렬은 대칭이 아님.

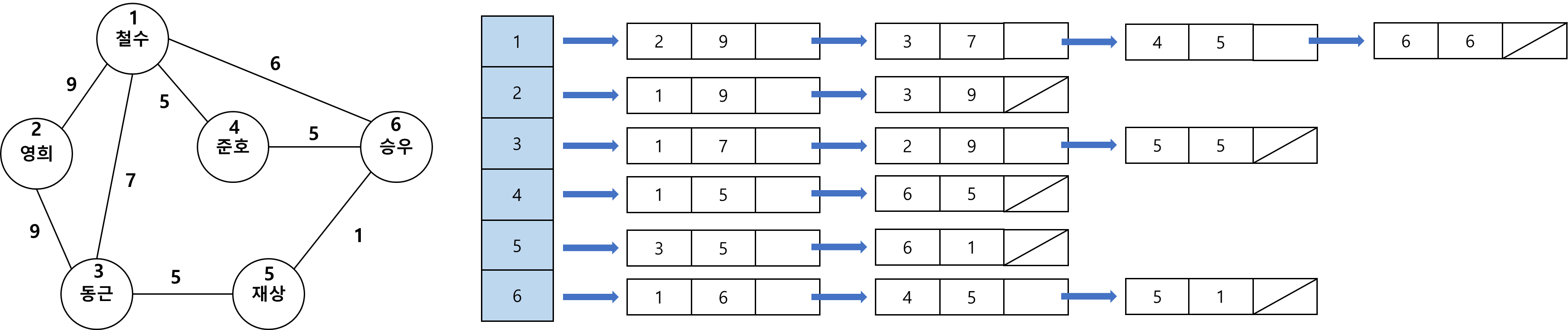
인접 리스트를 이용한 방법
- 각 정점에 인접한 정점들을 리스트로 표현하는 방법.
- 각 정점마다 리스트를 하나씩 만들고, 여기에 각 정점에 인접한 정점들을 연결 리스트로 매닮.
- 인접 리스트 표현에서는 행렬 표현과 달리 존재하지 않는 간선은 표현상에 나타나지 않음.
- 인접 리스트는 공간이 간선의 총수에 비례하는 양만큼 필요하므로 대체로 행렬 표현에 비해 공간의 낭비가 없음.
- 모든 가능한 정점 쌍에 비해 간선의 수가 적을 때 특히 유용함.
- 하지만 거의 모든 정점 쌍에 대해 간선이 존재하는 경우에는 오히려 리스트를 만드는 데 필요한 오버헤드만 더 들게 됨.
- 인접 리스트는 정점 i와 정점 j간에 간선이 존재하는지 알아볼 때 리스트에서 차례대로 훑어야 하므로 인접 행렬 표현보다는 시간이 많이 걸림.
- 간선이 많은 경우에는 최악의 경우 n에 비례하는 시간이 들 수도 있음. <- 이 부분이 알고리즘의 성능에 치명적인 영향
1. 단순 관계 리스트
- 간선 하나에 대하여 노드가 2개씩 만들어짐. 각 노드는 정점 번호, 다음 정점의 포인터로 구성됨.
- 이런 무향 그래프를 위한 인접 리스트 표현에서 필요한 총 노드 수는 존재하는 총 간선 수의 2배.
- 정점 i와 정점 j가 인접하면 정점 i의 연결 리스트에 정점 j가, 정점 j의 연결 리스트에 정점 i가 매달려 한 간선당 노드가 2개씩 만들어지기 때문.
- 유향 그래프의 경우에는 간선 하나당 노드가 하나씩 존재함.

2. 가중치가 있는 그래프
- 각 노드에는 정점 번호, 다음 노드의 포인터와 함께 해당 간선의 가중치를 저장하는 부분이 추가됨.
- 각 노드는 정점 번호, 가중치, 다음 정점의 포인터로 구성됨.
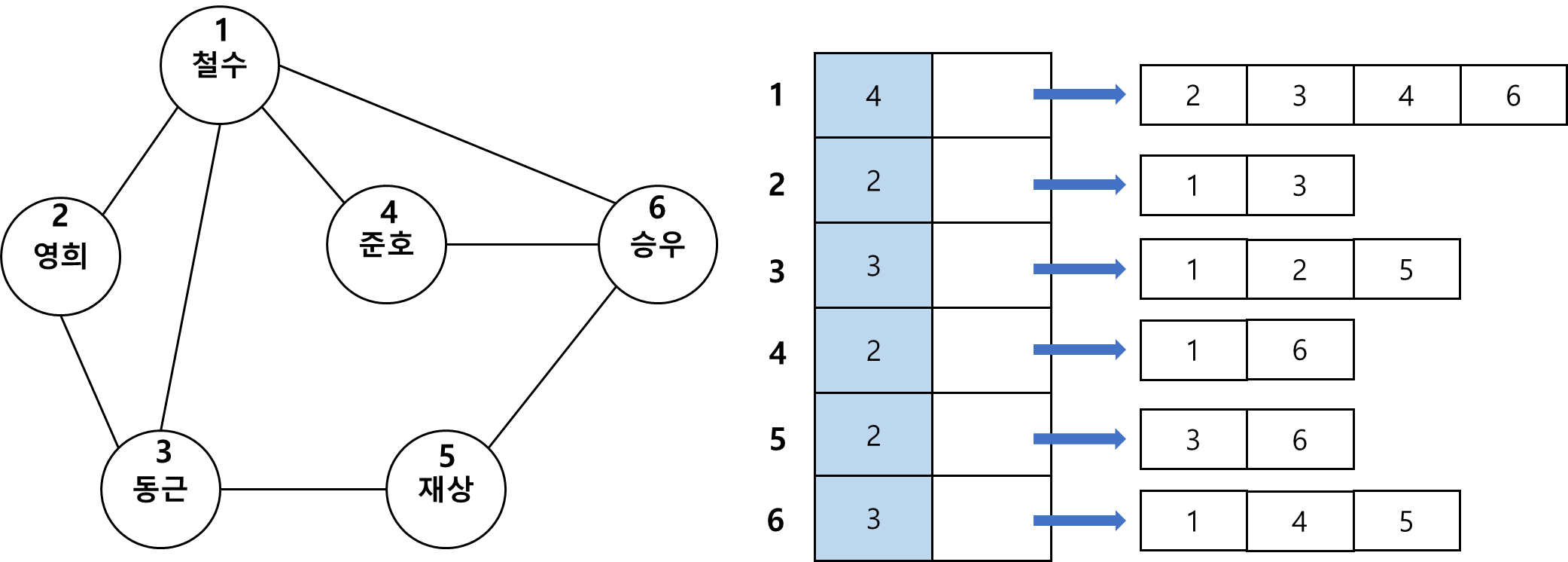
인접 배열과 인접 해시 테이블
- 연결이 그리 촘촘하지 않은 그래프라 하더라도 크기가 크면 인접 리스트를 쓰기가 만만치 않음.
- 특히 두 정점 간의 간선 존재 여부를 체크하는 일이 잦으면 수행 시간에 부담을 줌.
- 인접 리스트처럼 간선의 수에 비례하는 공간을 쓰면서 간선의 존재 여부를 훨씬 빨리 체크할 수 있는 방법이 있음.
- 각 정점에 연결된 정점들을 연결 리스트로 저장하는 대신 배열로 저장하면 연결 리스트의 포인터를 관리하는 번거로움에서 벗어나고, 두 정점의 인접 여부를 체크하는 시간도 단축됨.
- 배열을 정렬된 형태로 만들면 이진 탐색을 쓸 수 있어 임의의 정점에 인접한 정점 수가 k라면 log₂k + 1번 이내의 비교로 확인 가능함.
- 각 정점의 인접 배열 헤더에 인접 정점이 몇 개인지 표시해두면 탐색을 쉽게 할 수 있음.
인접 해시 테이블
- 각 인접 배열 크기의 두 배 정도의 공간을 할당하여 적재율을 0.5로 만들면 평균 2번 이내의 비교로 가능함.
- 원소 집합이 고정된 해시 테이블이므로 어느 정도 충돌이 일어나는지 미리 알 수 있음.
- 적재율을 마음대로 미리 정할 수 있음.
- 하지만 어떤 정점에서 인접한 정점들을 차례로 보면서 작업을 해야 할 경우에는 적합하지 않음.
- 임의의 두 정점이 인접한지만 체크하는 경우에는 아주 매력적임.
3. 너비 우선 탐색과 깊이 우선 탐색
- 모든 정점을 방문하는 방법은 다양하지만 대표적인 것이 너비 우선 탐색과 깊이 우선 탐색임.
- 두 방법은 매우 간단하지만 그래프 알고리즘에서 핵심적 위치를 차지함.
- 만일 분리된 두 개 이상의 부분 그래프가 있다면 BFS나 DFS를 부분 그래프의 수만큼 수행해야 모든 정점을 방문할 수 있음.
BFS
- 시작 정점을 제외한 모든 정점을 방문하지 않은 것으로 표시함.
- 큐의 맨 앞에 있는 정점을 빼내고 이에 인접한 정점 중 방문하지 않은 정점을 모두 방문한 것으로 표시하고 큐에 넣음.
- BFS가 수행되는 동안 enqueue()와 dequeue()를 각각 정확히 V번씩 호출함.
- BFS의 수행 시간은 Θ(V+E)
BFS(G,s)
{
for each v ∈ V-{s}
visited[v] <- NO ;
visited[s] <- YES;
enqueue(Q,x);
while ( Q ≠ Ø) {
u <- dequeue(Q);
for each v ∈ L(u) // L(u) : 정점 u의 인접 정점 집합
if ( visited[v] = NO ) then {
visited[v] <- YES;
enqueue(Q,v);
}
}
}
DFS
- 정점 v에 대해 DFS(v)가 호출되면 먼저 정점 v를 방문했다고 표시함.
- 이와 인접된 정점 중 방문하지 않은 정점에 대해 각각 DFS를 호출함.
- DFS(v)에서 x에 대해 DFS를 끝내고 돌아오면 방문하지 않은 상태였던 정점 y나 정점 z가 방문한 상태가 되어 이들에 대해 DFS를 수행할 필요가 없게 되는 상황은 매우 흔함.
- 궁극적으로 모든 정점에 대해 DFS()가 한 번씩 호출됨.
- DFS의 수행시간은 Θ(V+E)
DFS(v)
{
visited[v] <- YES;
for each x ∈ L(v) // L(v) : 정점 v의 인접 정점 집합
if ( visited[x] = NO ) then DFS(x);
}
4. 최소 신장 트리
- 그래프 G=(V,E)의 신장 트리는 정점 집합 V를 그대로 두고 간선을 |V| - 1개만 남겨 트리가 되도록 만든 것.
- 임의의 그래프로부터 만들 수 있는 신장 트리는 매우 다양함.
- 너비 우선 트리와 깊이 우선 트리도 신장 트리.
- 최소 신장 트리 : 간선들이 가중치를 갖는 그래프에서 간선 가중치의 합이 가장 작은 트리
프림 알고리즘
- 집합 S를 공집합에서 시작하여 모든 정점을 포함할 때까지(즉,S=V가 될때까지) 키워나감.
- 맨 처음 정점을 제외하고는 정점을 하나 더할 때마다 간선이 하나씩 확정됨.
Priim(G,r) // G : 주어진 그래프 , r : 시작 정점
{
s <- Ø; // S : 정점 집합
for each u ∈ V
d[u] <- ∞;
d[r] <- 0 ;
while ( S ≠ V ) {
u <- extractMin(V-S,d);
S <- S ∪ {u};
for each v ∈ L(u)
if ( v ∈ V-S and w(u,v) < d[u]) then {
d[v] <- w(u,v);
tree[v] <- u;
}
}
}
extractMin ( Q, d[] )
{
집합 Q에서 d값이 가장 작은 정점 u를 리턴함;
}
- 배열 d[]는 각 정점을 신장 트리에 포함시키는 데 드는 최소비용을 구하기 위한 것.
- 궁극적으로는 d[v]는 각 정점 v를 신장 트리에 연결하기 위해 드는 최소 비용을 갖게 되지만 알고리즘의 수행과정에서는 충분히 큰 값부터 시작하여 이 최소 비용을 향해 계속 감소함.
- tree[v]는 현재까지 계산 결과 정점 v를 신장 트리에 연결시키는 비용이 가장 적게 드는 간선을 저장함.
- 알고리즘이 끝난 후 이것을 이용해서 최소 신장 트리를 만들 수 있음.
Prim2(G,r)
{
Q <- V; // Q : S에 속하지 않은 정점 집합
for each u ∈ Q
d[u] <- ∞;
d[r] <- 0;
while ( Q ≠ Ø) {
u <- deletemin ( Q, d);
for each v ∈L(u)
if ( v ∈ Q and w(u,v) < d[v]) then {
d[v] <- w(u,v);
tree[v] <- u;
}
}
}
deleteMin ( Q, d[] )
{
집합 Q에서 d값이 가장 작은 정점 u를 리턴하고, u를 집합 Q에서 제거함;
}
- 집합 S를 제외한 나머지, 즉 Q = V-S를 중심으로 기술하였음.
- 이 변화 이외에는 완전히 똑같은 알고리즘.
- 이 알고리즘의 수행 시간은 처음 for 루프는 정확히 n회 반복함. 각각의 for 루프에서 단순 할당 작업을 하므로 상수 시간이 소모되어 for 루프는 총 O(v) 시간을 소요함.
- while 루프는 정확히 n회 반복됨. 이 while 루프에 for문이 중첩되어 있음.
- 두 개의 루프가 중첩되어 있지만 for 루프는 u와 인접한 간선을 훑어보는데 어떻게 되든 한 간선은 두 번만 봄.
- 그러므로 for 루프는 while 루프를 통틀어 2E번 돌 뿐임.
- 프림 알고리즘의 수행 시간은 deleteMin()이 while 루프가 반복될 때마다 수행되는 시간과 for 루프 내에서 수행되는 시간 중 하나가 좌우하게 됨.
- 프림 알고리즘의 수행 시간은 O(ElogV)가 됨.
크루스칼 알고리즘
- 사이클을 만들지 않는 범위에서 최소 비용 간선을 하나씩 더해가면서 최소 신장 트리를 만듦.
- n개의 정점으로 트리를 만드는 데는 n-1개의 간선이 필요하므로, 알고리즘은 최초에는 간선이 하나도 없는 상태에서 시작하여 n-1개의 간선을 더하면 끝남.
- 하나의 트리를 키워나가는 방식이 아니고, 임의의 시점에 최소 비용의 간선을 더하므로 여러 개의 트리가 산재하게 됨.
- 최초에는 n개의 트리로 시작함.
- 간선이 하나도 없는 상태의 n개의 정점은 각각 정점 하나만으로 구성된 n개의 트리로 볼 수 있음.
- n-1개의 간선을 더하고 나면 모든 트리가 합쳐져서 하나의 트리가 됨.
Kruskal(G)
{
T <- Ø; // 신장 트리
단 하나의 정점만으로 구성된 n개의 집합을 초기화함;
모든 간선을 가중치의 크기 순으로 정렬하여 배열 A[1 ... E]에 저장함;
while ( T의 간선 수 < n-1 ) {
A에서 최소 비용의 간선 (u,v)를 제거함;
if ( 정점 u와 v가 다른 집합에 속함 ) then {
T <- T ∪ {(u,v)};
정점 u와 v가 속한 두 집합을 하나로 합침;
}
}
}
크루스칼 알고리즘의 수행 시간 분석
- 모든 간선을 정렬하는 데 O(ElogE) = O(ElogV)가 소요됨.
- while 루프는 최소 V-1회, 최대 E회 반복됨.
- while 루프 내부를 보면 정렬된 배열에서 맨 앞부터 하나씩 제거해나가면 되므로 상수 시간이 듦.
- 집합을 관리하는 작업들로 여러 구현 방법이 있음. 최대 O(E)번의 Find-set()과 Union()을 수행하게 됨.
- V번의 Make-Set()이 필요함. 랭크를 이용한 Union과 경로 압축을 이용한 Find-Set을 사용하면 이들을 모두 합친 시간은 O((V+E)log*V)가 됨. 결국 크루스칼 알고리즘의 시간을 좌우하는 것은 정렬 시간.
- 따라서 총 수행 시간은 O(ElogV)가 됨.
안전성 정리
- 프림 알고리즘은 하나의 집합 S를 키워나가면서 하나의 신장 트리르 만드는 방식.
- 크루스칼 알고리즘은 여러 집합을 합쳐가면서 최종적으로 하나의 신장 트리를 만드는 방식.
- 프림 알고리즘은 집합 S에 정점을 하나씩 더해가지만 하나 더할 때마다 해당 정점을 트리에 연결하는 간선이 정해지므로 사실상 간선을 하나씩 더하는 것.
- 크루스칼 알고리즘은 두 개의 집합을 합칠 때마다 두 집합을 연결하는 하나의 간선이 정해지므로 역시 간선을 하나씩 더하는 것. 따라서 두 알고리즘 모두 n-1개의 간선을 더해가는 순서를 나름대로 정해줌.
- 이렇게 더해가는 간선이 궁극적으로 최소 신장 트리에 이르는 길을 놓치지 않아 해당 간선을 일단 중간 과정에 포함시키는 것이 안전함.
5. 위상 정렬
- 작업 i와 작업 j 사이에 간선(i,j)가 존재한다면 작업 i는 반드시 작업 j보다 먼저 수행. 모든 간선에 대해서 이 성질만 만족한다면 어떤 순서라도 괜찮음.
- 이런 성질을 만족하는 정렬을 위상 정렬이라 함.
- 사이클이 없는 유향 그래프 G=(V,E)에서 V의 모든 정점을 정렬하되, 간선(i,j)가 존재하면 정렬 결과에서 정점 i는 반드시 정점 j보다 앞에 위치해야 함.
- 만약 그래프에 사이클이 있다면 이 성질은 결코 만족될 수 없으므로 위상 정렬은 할 수 없음.
- 정점이 제거되는 순서가 하나의 위상 정렬을 이룸.
topologicalSort1(G,v)
{
for i <- 1 to n {
진입 간선이 없는 정점 u를 선택함;
A[i] <- u ;
정점 u와 u의 진출 간선들을 모두 제거함;
}
// 배열 A[1 ... n]에는 정점들이 위상 정렬되어 있음.
}
위상 정렬 알고리즘의 수행시간
- for 루프는 n번 반복됨.
- 매 반복 때마다 1개의 정점이 선택되고 해당 정점에 연결된 진출 간선이 모두 제거됨.
- 각 간선은 단 한 번씩만 취급됨.
- 그러므로 총 수행 시간은 Θ(V+E)임.
또 다른 위상 정렬 알고리즘
- DFS를 이용한 것으로 앞의 알고리즘보다 더 많이 사용됨.
- DFS를 거의 그대로 이용하면서 약간의 요소만 더 추가되어 두 번째 알고리즘이 더 구현하기 간단함.
- DFS와 다른 점은 함수의 맨 끝에 작업이 끝난 정점을 연결 리스트로 관리하는 부분.
topologicalSort2(G)
{
for each v ∈ V
visited[v] = NO;
for each v ∈ // 정점의 순서는 무관
if ( visited[v] = NO ) then DFS-TS(v);
}
DFS-TS(v)
{
visited[v] = YES;
for each x ∈ L(v)
if ( visited[v] = NO ) then DFS-TS(x);
연결 리스트 R의 맨 앞에 정점 v를 삽입함;
}
- 아무 정점이나 택하여 DFS-TS를 시작하면 해당 정점의 진출 간선이 있는만큼 방문하면서 끝부터 할 일이 없으면 번호를 부여하고 이전 정점으로 되돌아옴.
- 최종적으로 연결 리스트 R에는 완료 순서의 역순으로 정점들이 저장되어 있음.
알고리즘의 수행 시간
- DFS에 연결 리스트 삽입을 더한 것뿐이므로 (연결 리스트 삽입 한 번당 상수 시간, 총 Θ(V)) DFS의 수행시간과 같음. 그러므로 Θ(V+E)임.
6. 최단 경로
다익스트라 알고리즘 (음의 가중치를 허용하지 않는 경우)
- 입력 그래프 G=(V,E)에서 간선들의 가중치가 모두 0 이상인 경우의 최단 경로 알고리즘.
Dijkstra(G,r)
{
S <- Ø; // S : 정점 집합
for each u ∈ V
d[u] <- ∞ ;
d[r] <- 0;
while (S≠V) { //n회 순환
u <- extractMin(V-S,d);
S <- S ∪ {u};
for each v ∈ L(u) // 정점 u로부터 연결된 정점들의 집합
if ( v ∈ V-S and d[v] + w(u,v) < d[v] ) then {
d[v] <- d[u] + w(u,v);
prev[v] <- u;
}
}
}
extractMin(Q,d[])
{
집합 Q에서 d값이 가장 작은 정점 u를 리턴함;
}
- 다익스트라 알고리즘은 프림 알고리즘과 원리가 거의 같음.
- d[v]가 정점 r에서 정점 v에 이르는 최단 거리를 위해 사용됨.
- 다익스트라 알고리즘은 간선의 가중치가 음이 되면 작동하지 않음.
- 다익스트라 알고리즘은 프림 알고리즘과 거의 동일하여 수행시간은 동일함.
- 힙을 이용하면 O(ElogV) 시간이 소요됨.
벨만-포드 알고리즘 (음의 가중치를 허용하는 경우)
- 입력 그래프 G=(V,E)에서 간선의 가중치가 음의 값을 허용하는 임의의 실수인 경우 최단 경로 알고리즘임.
- 간선을 최대 1개 사용하는 최단 경로, 간선을 최대 2개 사용하는 최단 경로, . . . 식으로 간선을 최대 n-1개 사용하는 최단 경로까지 구해나감.
BellmanFord(G,r)
{
for each u ∈ V
d[u] <- ∞;
d[r] <- 0;
①for i <- 1 to |V| - 1
②for each (u,v) ∈ E
if ( d[u] + w(u,v) < d[v] ) then {
③d[v] <- d[u] + w(u,v);
prev[v] <- u;
}
// 음의 사이클 존재 여부 확인
④for each (u,v) ∈ E
if ( d[u] + w[u,v] < d[v] ) then output "음의 사이클 발견! 해 없음";
}
- ①의 for 루프는 총 n-1번 반복됨. i번째 루프가 끝나면 최대 i개의 간선을 사용해서 이를 수 있는 최단 경로가 계산됨.
벨만-포드 알고리즘의 수행 시간 분석
- ①의 for 루프는 O(V)회 반복됨.
- ②의 for 루프는 O(E)회 반복됨.
- ②의 for 루프 내 if ~ then 작업은 상수 시간 작업임. 따라서 이 두 for 루프가 겹쳐져서 총 O(VE) 시간이 소요됨.
- ④의 for 루프는 상수 시간이 소요되는 일이 O(E)회 반복되므로 O(E) 시간이 듦.
∴ 벨만-포드 알고리즘 수행 시간 : O(VE)
모든 쌍 최단 경로 알고리즘
- 모든 정점 쌍 사이의 최단 경로를 구하는 방법.
- 구해야 할 최단 경로가 모두 n²개.
- 이 알고리즘은 동적 프로그래밍을 이용한 기발한 해결책을 제시함.
플로이드 워샬 알고리즘
Floyd_Warshall()
{
for k <- 1 to n
for i<- 1 to n
for j <- 1 to n
d[i][j] = min( d[i][j], d[i][k] + d[k][j] ) ;
}
- 이 알고리즘의 수행 시간은 Θ(n)의 for루프가 3번 중첩되었고, 각 경우에 단 두 가지 경우의 대소를 비교하는 것이므로 상수 시간이 걸려 Θ(n³) 시간에 수행됨.
사이클이 없는 그래프의 최단 경로
- 사이클이 없는 그래프에서 최단 경로를 구하는 것은 간단함.
- 사이클이 없는 유향 그래프를 DAG라 함.
- DAG에서는 모든 정점을 한 줄로 늘어놓을 때, 뒤에 위치한 정점부터 앞에 위치한 정점으로 가는 간선은 존재하지 않도록 하는 정점들의 순열이 존재함.
- 이 순열은 위상 정렬로 얻을 수 있음.
DAG-ShortestPath(G,r)
{
①for each u ∈ V
d[u] <- ∞;
d[r] <- 0;
②G의 정점들을 위상 정렬함;
③for each u ∈ V (위상 정렬 순서로)
④for each v ∈ L(u) // L(u) : u로부터 연결된 정점들의 집합
if ( d[u] + w(u,v) < d[v] ) then {
d[v] <- d[u] + w(u,v);
prev[v] <- u;
}
}
7. 강연결 요소
- 유향 그래프 G=(V,E)에서 V의 모든 정점 쌍(u,v)에 대해서 경로 u->v와 경로 v->u가 존재하면 G는 강하게 연결된 것.
- 어떤 두 정점을 잡더라도 양방향으로 서로에게 이르는 경로가 존재하면 강하게 연결되었다고 함.
- 그래프에서 강하게 연결된 부분 그래프들을 각각 강연결 요소라고 함.
- 임의의 그래프에서 강연결 요소들을 찾는 문제는 깊이 우선 탐색을 이용하는 대표적인 응용 중 하나.
stronglyConnectedComponents(G)
{
①그래프 G에 대해 DFS를 수행하여 각 정점 v의 완료 시간 f[v]를 계산함;
②G의 모든 간선들의 방향을 뒤집어 G'을 만듦.
③그래프 G'에 대해 DFS를 수행하되 ①에서 구한 f[v]가 가장 큰 정점으로 잡음;
④앞의 ③에서 만들어진 분리된 트리 각각을 강연결 요소로 리턴함.
}
강연결 요소 알고리즘 수행시간
- DFS는 Θ(V+E) 시간이 듦.
- 그래프 G'을 만드는 과정도 모든 간선을 훑으면서 방향만 바꾸면 되므로 Θ(V+E)
- 그러므로 알고리즘의 총 수행 시간은 Θ(V+E)임.
'개인 공부 > 알고리즘' 카테고리의 다른 글
| [알고리즘] 문자열 매칭 (0) | 2023.03.04 |
|---|---|
| [알고리즘] 그리디 알고리즘 (0) | 2023.03.01 |
| [알고리즘] 동적 프로그래밍 (1) | 2023.02.18 |
| [알고리즘] 집합의 처리 (1) | 2023.02.17 |
| [알고리즘] 해시 테이블 (0) | 2023.02.14 |


