
- Android
- kubeflow
- 2023_1st_Semester
- 티스토리챌린지
- app
- Operating_System
- Personal_Study
- 오블완
- Linux
- Database_Design
- Artificial_Intelligence
- datastructure
- Python
- programmers
- Baekjoon
- tensorflow
- 리눅스마스터2급
- cloud_computing
- 자격증
- codingTest
- Image_classification
- Algorithm
- Unix_System
- Java
- Kubernetes
- Univ._Study
- study
- SingleProject
- c++
- C
코딩 기록 저장소
[알고리즘] 검색 트리 본문
1. 레코드, 키의 정의 및 검색 트리
레코드
- 개체에 대한 모든 정보를 포함.
- 각각의 정보를 나타내는 부분을 필드라고 함.
- 검색트리에 레코드 전부 저장 가능하지만 보통은 해당 레코드를 대표할 수 있는 필드만으로 검색트리를 만듦.
키
- 다른 레코드와 중복되지 않으면서 레코드를 대표할 수 있는 필드를 검색키 또는 키라고 함.
- 키는 필드 하나로 구성할 수도 있고, 복수 개의 필드로 구성할 수도 있음.
검색 트리
- 한 노드에서 최대 몇 개의 자식 노드로 분기를 할 수 있느냐에 따라 이진 검색 트리와 다진 검색 트리로 나눔.
- 이진 검색 트리는 최대 두 개의 자식 노드를 가질 수 있고, 다진 검색 트리는 세 개 이상의 자식 노드로 분기 가능.
- 일반적으로 k진 검색 트리라 하면 자식을 최대 k개까지 가질 수 있는 검색 트리를 뜻함.
- 저장되는 장소에 따라 내부 검색 트리와 외부 검색 트리로 나눔.
- 내부 검색 트리는 검색 트리가 메인 메모리 내에 존재함.
- 외부 검색 트리는 검색 트리가 외부(주로 디스크)에 존재함.
- 검색키가 포함하는 필드의 수에 따라 일차원 검색 트리와 다차원 검색 트리로 나눔.
2. 이진 검색 트리
이진 검색 트리의 특징
1. 이진 검색 트리의 각 노드는 키 값을 하나씩 가짐. 각 노드의 키 값은 모두 달라야 함.
2. 최상위 레벨에 루트 노드가 있고, 각 노드는 최대 두 개의 자식 노드를 가짐.
3. 임의의 노드의 키 값은 자신의 왼쪽에 있는 모든 노드의 키 값보다 크고, 오른쪽에 있는 모든 노드의 키 값보다 작음.
이진 검색 트리에서 검색
- 이진 검색 트리에서 키가 x인 노드를 검색함.
- 키가 x인 노드가 존재하면 해당 노드를 리턴하고, 존재하지 않으면 NIL을 리턴함.
treeSearch(t,x)
{
① if ( t = NIL or key[t] = x ) then return t;
if ( x < key[t] )
② then return treeSearch(left[t],x);
③ then return treeSearch(right[t],x);
}
- 알고리즘의 입력으로는 검색할 트리의 루트 노드 t와 검색하고자 하는 키 x가 주어짐.
- ① 찾고자 하는 값이 존재하지 않거나 t이면 t를 리턴함.
- ② 만약 찾고자 하는 값이 t의 키 값보다 작으면 t의 왼쪽 서브 트리로 가서 x를 찾음.
- ③ 만약 찾고자 하는 값이 t의 키 값보다 크면 t의 오른쪽 서브 트리로 가서 x를 찾음.
이진 검색 트리에서 삽입
- 원소 x를 이진 검색 트리에 삽입하려면 이진 검색 트리에 x를 키 값으로 가진 노드가 없어야 함.
- 원소 x를 삽입할 자리를 찾기 위해서는 실패하는 검색을 한 번 수행해야함.
- 루트 노드에서 x에 대한 검색을 수행해 임의의 리프 노드에서 더 이상 내려갈 곳이 없음이 확인되면 x를 그 리프 노드의 자식으로 추가함.

treeinsert(t, x)
{
if ( t = NIL ) then {
key[r] <- x;
left[r] <- NIL;
right[r] <- NIL ;
return r;
}
if ( x < key[t] )
① then { left[t] <- treeInsert(left[t], x); return t; }
② else { right[t] <- treeInsert (right[t], x); return t; }
}
- 균형이 잘 맞는 트리면 검색의 효율이 높음. 검색 트리에서 효율은 검색 트리의 깊이와 밀접한 상관이 있기 때문.
- 하지만 트리의 균형이 잘 맞지 않는 경우도 발생함. 이때에는 검색의 효율이 나쁨.
- n개의 원소로 이진 검색 트리를 만들 때, 이진 검색 트리가 가장 이상적으로 균형이 잡히면 최악의 경우라 하더라도 검색 시간은 θ(log n)임.
- 가장 나쁘게 기울면 평균 검색 시간이 θ(n)이 됨.
이진 검색 트리에서 삭제
- 삽입은 노드가 삽입될 자리만 정해지면 간단하지만, 삭제의 경우는 더 복잡함.
- 이진 검색 트리에서 노드 r을 삭제하고자 할 때는 세가지의 경우에 따라 각각 다르게 처리를 해주어야 함.
Case 1 : r이 리프 노드인 경우
- 리프 노드이므로 자식이 없어 삭제되어도 아래쪽에는 영향을 미치지 않음.
- 부모 노드에서 r을 가리키고 있던 포인터를 NIL로만 바꾸어주면 됨.

Case 2 : r의 자식 노드가 하나인 경우
- r을 제거하면 r의 자식 노드로의 연결이 끊어져버림
- r의 부모 노드에서 r을 가리키고 있던 포인터를 r의 자식을 가리키도록 바꾸어주면 됨.

Case 3 : r의 자식 노드가 두개인 경우
- r의 자리에 옮겨놓아도 이진 검색 트리의 성질을 전혀 깨지 않는 원소를 찾아야함.
- r의 왼쪽 서브트리에서 가장 큰 원소와 r의 오른쪽 서브 트리에서 가장 작은 원소 중 하나를 택해 r의 자리로 옮김.
- 그 다음 직후 원소가 들어 있던 노드를 삭제함.

treeDelete(t, r, p) // t : 트리의 루트 노드 , r : 삭제하고자 하는 노드, p : r의 부모 노드
{
// r이 루트 노드인 경우
if ( r = t ) then root <- deleteNode(t);
// r이 루트 노드가 아닌 경우
else if ( r = left[p] )
then left[p] <- deleteNode(r); //r이 p의 왼쪽 자식
else right[p] <- deleteNode(r); // r이 p의 오른쪽 자식
}
deleteNode(r)
{
if (left[r] = right[r] = NIL ) then return NIL;
else if (left[r] = NIL and right[r] ≠ NIL ) then return right[r];
else if (left[r] ≠ NIL and right[r] = NIL ) then return left[r];
else {
s <- right[r];
while ( left[s] ≠ NIL )
{ parent <- s; s<-left[s]; }
key[r] <- key[s];
if (s=right[r]) then right[r] <- right[s];
else left[parent] <- right[s];
return r;
}
- 삭제 작업을 위한 최악의 시간은 트리의 높이에 따라 O(log n)과 O(n) 사이에서 결정됨.
3. 레드 블랙 트리
- 이진 검색 트리는 저장과 검색에 평균 θ(log n) 시간이 소요되지만 운이 나쁘면 트리의 모양이 균형을 잘 이루지 못함.
- 균형이 많이 깨지면 θ(n)에 근접한 시간이 소요될 수도 있음 -> 그래서 고안해낸 것이 균형잡힌 이진 검색 트리
- 균형잡힌 이진 검색 트리는 최악의 경우에도 이진 트리의 균형이 잘 맞도록 유지함.
- 균형잡힌 이진 검색 트리로 대표적인 것은 레드 블랙 트리와 AVL 트리임.
레드 블랙 트리
- 이진 검색 트리의 모든 노드에 레드 또는 블랙의 색상을 칠함.
- 레드 블랙 특성
1. 루트는 블랙임.
2. 모든 리프는 블랙임.
3. 노드가 레드이면 그 노드의 자식은 반드시 블랙임.
4. 루트 노드에서 임의의 리프 노드에 이르는 경로에서 만나는 블랙 노드의 수는 모두 같음.
- 여기서 말하는 리프 노드는 일반적으로 말하는 리프 노드와 의미가 다름.
- 이진 검색 트리의 노드가 가진 두 개의 자식 포인터 중 NIL인 것이 있으면 노드를 하나 만들어 그것을 리프 노드라 함.

- 레드 블랙 트리에서 검색은 트리의 내용을 건드리지 않으므로 이진 검색 트리에서 검색과 동일함.
- 삽입과 삭제도 기본적으로는 이진 검색 트리와 동일하지만 삽입이나 삭제 후 레드 블랙 특성을 위반하는 경우가 발생할 수 있음
- 이때 적절한 작업을 통해 특성을 만족하도록 바로잡아 주어야 함.
레드 블랙 트리에서 삽입
- 레드 블랙 트리에서 노드를 삽입할 때는 먼저 이진 검색 트리의 삽입 알고리즘에 따라 삽입을 한 다음 새 노드의 색상을 레드로 칠함.
- 새 노드는 항상 맨 아래쪽에 존재함. 삽입 직후에 노드의 아래쪽은 블랙 노드인 리프 2개만 있어 레드 블랙 특성에서 문제가 생기지 않음.
- 새 노드의 위쪽과 관련해서 문제가 생기는지 확인해야 함.
- 새 노드의 부모 노드p가 블랙이면 삽입은 완료됨.
- p가 레드인 경우, p의 부모 노드 pp는 반드시 블랙임. 새 노드의 주변에서 레드나 블랙 두 가지가 다 가능한 것은 p의 형제 노드 s뿐임.
Case 1 : s가 레드
- p와 s의 색상을 레드에서 블랙으로 바꾸고, pp의 색상을 블랙에서 레드로 바꿈.
- 이때 pp가 루트이면 다시 블랙으로 바꾸고 끝나고, 루트가 아니면 부모 색상을 확인해야함.
- 블랙이면 레드 블랙 특성이 모두 만족되고, 레드이면 처음과 똑같은 문제가 발생함.
- pp를 문제 발생 노드로 하여 재귀적으로 다시 시작함.
- 상황이 끝날 수도 있고 똑같은 상황이 다른 노드에서 다시 시작될 수도 있음. 이런 상황이 재귀적으로 반복되어 루트까지 올라갈 수도 있음.
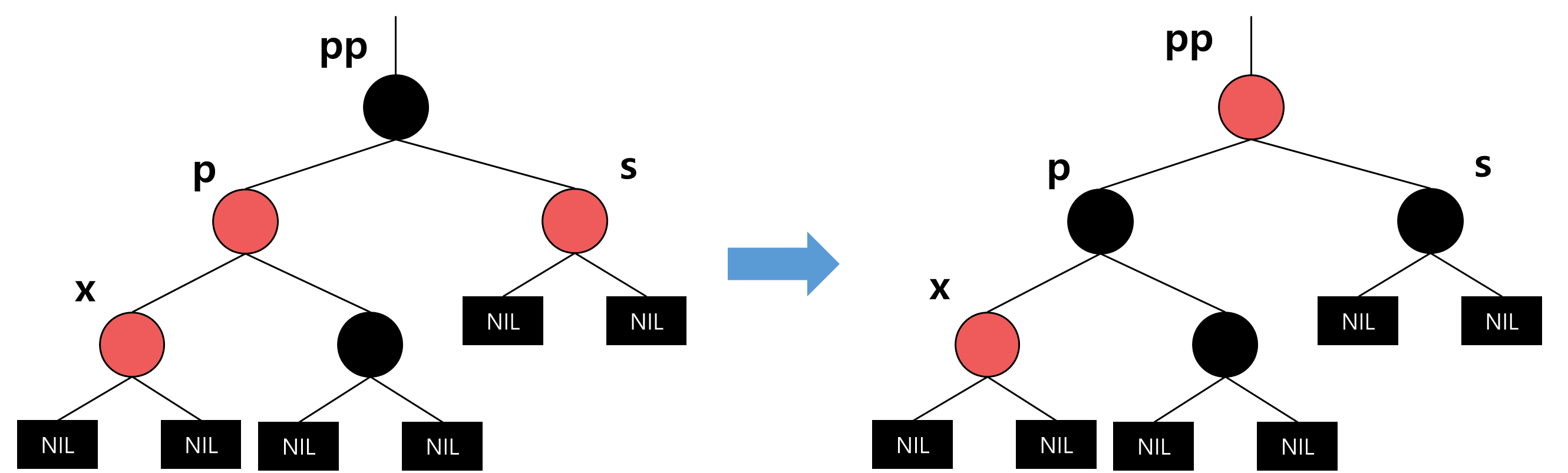
Case 2 : s가 블랙
1. 새 노드가 p의 오른쪽 자식
- p를 중심으로 왼쪽으로 회전함. 여전히 레드 블랙 특성 3번을 위반함.
- 2번으로 이동함.
2. 새 노드가 p의 왼쪽 자식
- pp를 중심으로 오른쪽으로 회전하고 p와 pp의 색상을 맞바꿈.
- 이 수선을 마지막으로 상황이 종료됨.
레드 블랙 트리에서 삭제
- 기본적으로 이진 검색 트리에서 삭제 방법에 따라 노드를 삭제한 후 색상을 맞추어줌.
- 이진 검색 트리에서 임의의 노드 d를 삭제할 때 d의 자식이 둘이면 d의 오른쪽 서브 트리에서 최소 원소를 가진 노드 m의 키를 노드 d로 옮긴 다음 노드 m을 삭제함.
- 노드 d의 색상을 건드리지 않은 채 키만 바뀌는 것은 레드 블랙 특성에는 영향을 미치지 않음.
- 문제가 되는 것은 최소 원소 노드 m을 삭제한 후 m 주변의 레드 블랙 특성의 위반 여부임.
- 최소 원소 노드 m은 왼쪽 자식을 갖지 않아 최대 한 개의 자식만을 가질 수 있으므로 두 개의 자식을 가진 노드의 삭제 작업은 자식이 없거나 한 개 만을 가진 노드의 삭제 작업으로 귀결됨.

- 삭제하려고 하는 노드 m의 자식을 x라고 함.
- 자식이 없으면 x는 NIL 노드가 됨.
- m은 자기 부모 노드의 왼쪽 자식일 수도 있고, 오른쪽 자식일 수도 있음. 두 경우는 대칭적임.
1. 삭제 노드가 레드
- m이 레드이면 삭제 후 아무런 조치가 필요 없음. ( 레드 블랙 특성을 깨지 않음 )

2. 삭제 노드가 블랙
- m이 블랙이더라도 x가 레드이면 삭제 후 x의 색상을 블랙으로 바꾸어버리면 레드 블랙 특성을 만족함.

- 먼저 p의 색상에 따라 Case 1(레드)과 Case 2(블랙)로 나눔.
Case 1 : p가 레드(s는 반드시 블랙). <I의 색상,r의 색상>에 따라
- Case 1-1 <블랙,블랙>
- Case 1-2 <레드,레드> 또는 <블랙,레드>
- Case 1-3 <레드,블랙>
- p가 블랙이면 s는 블랙, 레드가 모두 가능함.
'개인 공부 > 알고리즘' 카테고리의 다른 글
| [알고리즘] 집합의 처리 (1) | 2023.02.17 |
|---|---|
| [알고리즘] 해시 테이블 (0) | 2023.02.14 |
| [알고리즘] 선택 알고리즘 (0) | 2023.02.10 |
| [알고리즘] 정렬 (0) | 2023.02.08 |
| [알고리즘] 점화식과 알고리즘 복잡도 분석 (0) | 2023.02.08 |



